1.6. Однострочники для анализа данных
1.6.1. Разбор JSON для получения статистики из GitHub
Рассмотрим задачу получения сведений о git-репозиториях пользователя GitHub посредством взаимодействия по протоколу HTTP (Hypertext Transfer Protocol) с удалённым API (Application Programming Interface), возвращающим данные в формате JSON [15]. Отправка запросов и разбор ответов сервера будет осуществляться при помощи утилит командной оболочки Linux. Полученные сведения о репозиториях будут включать их имена и число «звёзд», равное количеству пользователей, добавивших репозиторий в список «избранное».
Начнём с получения списка репозиториев пользователя в формате JSON. В GitHub HTTP API настроены лимиты на число запросов в час, поэтому при помощи утилиты curl отправим единственный HTTP-запрос к API и, воспользовавшись оператором перенаправления вывода >, сохраним результат в файл repos.json. Получим список репозиториев, владельцем которых является пользователь GitHub с именем true-grue:
~$ curl -s https://api.github.com/users/true-grue/repos > repos.json
~$ cat repos.json | head -n 5
[
{
"id": 207806577,
"node_id": "MDEwOlJlcG9zaXRvcnkyMDc4MDY1Nzc=",
"name": "algomusic",
Опция -s используется для отключения вывода диагностических сообщений утилиты curl. Файл repos.json теперь содержит массив объектов со сведениями о репозиториях пользователя GitHub true-grue. В вывод, ограниченный первыми 5 строками, включён идентификатор и имя репозитория algomusic.
Для обработки полученного массива объектов со сведениями о репозиториях воспользуемся утилитой jq [17], предназначенной для преобразования строк в формате JSON и для извлечения данных из них. Утилиту jq версии не ниже 1.6 потребуется установить дополнительно при помощи Вашего пакетного менеджера. Начнём с извлечения объектов из массива, содержащегося в файле repos.json:
~$ cat repos.json | jq '.[0]' | head -n 5
{
"id": 207806577,
"node_id": "MDEwOlJlcG9zaXRvcnkyMDc4MDY1Nzc=",
"name": "algomusic",
"full_name": "true-grue/algomusic",
~$ cat repos.json | jq '.[1]' | head -n 5
{
"id": 427108160,
"node_id": "R_kgDOGXUnQA",
"name": "awesome-russian-cs-books",
"full_name": "true-grue/awesome-russian-cs-books",
Выражение .[i] в списке параметров jq используется для получения \(i\)-го элемента из массива JSON-объектов: выражение .[0] позволяет получить первый элемент массива, а выражение .[1] – второй элемент.
Теперь извлечём имена репозиториев из JSON-объектов по ключу name:
~$ cat repos.json | jq '.[0].name'
"algomusic"
~$ cat repos.json | jq '.[1].name'
"awesome-russian-cs-books"
Для извлечения нескольких значений по нескольким ключам можно воспользоваться оператором конвейера | внутри строки запроса jq. В этом случае каждое полученное значение будет размещено на новой строке:
~$ cat repos.json | jq '.[0] | (.name, .stargazers_count)'
"algomusic"
11
~$ cat repos.json | jq '.[1] | (.name, .stargazers_count)'
"awesome-russian-cs-books"
38
Значения из JSON, имеющие строковой тип данных, выведены в stdout с обрамляющими двойными кавычками, а числовые значения выведены без кавычек. В случае, если необходимо соединить значения полей, можно воспользоваться оператором конкатенации строк +, но числа при этом необходимо явно преобразовать в строки при помощи оператора tostring. Кроме того, подобное преобразование легко применить сразу ко всем JSON-объектам в массиве, заменив .[0] на .[]:
~$ cat repos.json | jq '.[] | (.name + " " + (.stargazers_count | tostring))' | head -n 5
"algomusic 11"
"awesome-russian-cs-books 38"
"ayumi 88"
"BytePusher 6"
"code-snippets 3"
Отсортируем полученный перечень репозиториев по их числу «звёзд», равному количеству добавлений репозиториев в список «избранное» пользователями GitHub. Для этого воспользуемся стандартной утилитой sort, предварительно заменив двойные кавычки на пустые строки утилитой sed:
~$ cat repos.json | jq '.[] | (.name + " " + (.stargazers_count | tostring))' | sed 's/"//g' | sort -k 2 -n -r | head -n 5
Compiler-Development 498
kispython 203
ayumi 88
kisscm 84
raddsl 83
Команда s утилиты sed имеет синтаксис s/шаблон/замена/опции, а опция g переключает утилиту sed в режим глобального поиска и замены. С опцией g вместо однократной замены все двойные кавычки заменятся на пустые строки. Опция -k утилиты sort позволяет указать номер колонки, по которому необходимо упорядочить строки, при этом в качестве разделителя колонок используется пробел. Опция -n включает численную сортировку, а опция -r меняет порядок сортировки на обратный.
Преобразуем результат в формат csv, заменив пробел на запятую при помощи утилиты tr, и выведем в stdout таблицу с данными:
~$ cat repos.json | jq '.[] | (.name + " " + (.stargazers_count | tostring))' | sed 's/"//g' | sort -k 2 -n -r | tr ' ' ',' | csvlook -H | head -n 7
| a | b |
| -------------------- | --- |
| Compiler-Development | 498 |
| kispython | 203 |
| ayumi | 88 |
| kisscm | 84 |
| raddsl | 83 |
Для вывода на экран оформленной таблицы мы воспользовались утилитой csvlook из пакета утилит csvkit [18]. Пакет утилит csvkit версии не ниже 2.0.1 потребуется установить дополнительно при системного пакетного менеджера или пакетного менеджера PyPI. Опция -H утилиты csvlook позволяет использовать имена колонок по умолчанию, поскольку наш вывод в формате csv не содержит строки-заголовка. В качестве имён колонок в csvlook с опцией -H используются буквы английского алфавита.
Добавим строку-заголовок к выводу в формате csv при помощи AWK [19]:
~$ cat repos.json | jq '.[] | (.name + " " + (.stargazers_count | tostring))' | sed 's/"//g' | sort -k 2 -n -r | tr ' ' ',' | awk 'BEGIN { print "Репозиторий,Звёзд" } { print }' | csvlook | head -n 7
| Репозиторий | Звёзд |
| -------------------- | ----- |
| Compiler-Development | 498 |
| kispython | 203 |
| ayumi | 88 |
| kisscm | 84 |
| raddsl | 83 |
В языке AWK инструкция в фигурных скобках, указанная после ключевого слова BEGIN, выполняется однократно в момент начала выполнения команды, и в результате в вывод попадает строка Репозиторий,Звёзд. Инструкция print, указанная следующей также в фигурных скобках, выполняется для каждой строки, поступившей на вход утилите awk через stdin.
Полученный набор команд, объединённых оператором конвейера |, можно упростить, возвращая несколько строк после разбора JSON утилитой jq и объединяя полученные пары строк в одну утилитой xargs со значением параметра -n, равным 2. В случае, если утилита jq вызывается с опцией необработанного вывода -r, нет необходимости в преобразовании типов данных функцией tostring и в удалении двойных кавычек – в stdout значения полей name и stargazers_count попадут как строки, не обрамлённые кавычками. Кроме того, заменять символ пробела на запятую при формировании csv можно прямо в программе на языке AWK, без задействования утилиты tr. Объединим все инструкции в один конвейер:
~$ curl -s https://api.github.com/users/true-grue/repos \
> | jq -r '.[] | (.name, .stargazers_count)' \
> | xargs -n 2 \
> | sort -nrk2 \
> | awk 'BEGIN { print "Репозиторий,Звёзд" } { print $1 "," $2 }' \
> | csvlook \
> | head -n 7
| Репозиторий | Звёзд |
| -------------------- | ----- |
| Compiler-Development | 498 |
| kispython | 203 |
| ayumi | 88 |
| kisscm | 84 |
| raddsl | 83 |
В приведённом примере кода символ \ используется для игнорирования служебного символа переноса строки \n. Это позволяет разбивать на несколько строк длинные команды, в которых разные утилиты объединяются в одну команду при помощи оператора конвейера |.
При помощи реализованного конвейера легко получить статистику по репозиториям другого пользователя, заменив имя пользователя true-grue в ссылке, являющейся параметром утилиты curl. Попробуем в таком же формате вывести сведения о репозиториях, к которым имеет доступ пользователь GitHub worldbeater – такой фильтр можно включить, установив параметр строки запроса type равным значению member. Переносить фрагменты команды на новую строку можно и без использования символа \, как в предыдущем примере – достаточно закончить строку оператором конвейера |:
~$ curl -s https://api.github.com/users/worldbeater/repos?type=member |
jq -r '.[] | (.name, .stargazers_count)' |
xargs -n 2 |
sort -nrk2 |
awk 'BEGIN { print "Репозиторий,Звёзд" } { print $1 "," $2 }' |
csvlook |
head -n 7
| Репозиторий | Звёзд |
| --------------------- | ----- |
| Camelotia | 567 |
| Citrus.Avalonia | 565 |
| Live.Avalonia | 409 |
| ReactiveUI.Validation | 245 |
| ReactiveMvvm | 180 |
Реализованный конвейер показан на рис. 5:

Белом цветом на рис. 5 выделены стандартные утилиты командной оболочки Linux, серым цветом выделены утилиты jq [17] и csvlook [18], которые были установлены отдельно при помощи пакетного менеджера.
1.6.2. Разбор XLSX для поиска бассейнов
В этом разделе рассмотрим задачу обработки табличных данных в формате XLSX (Excel Spreadsheet), полученных из Портала открытых данных Правительства Москвы [20] и содержащих сведения о крытых плавательных бассейнах города, для поиска бассейнов длиной более 25 метров. Начнем с экспорта данных в формате XLSX со страницы [20]. Загрузить данные со страницы [20] можно, нажав на кнопку «экспорт» и выбрав предпочтительный формат или воспользовавшись утилитой curl, указав через опцию -o имя файла, в который необходимо сохранить загруженный ZIP-архив с таблицей:
~$ curl -s -o data.zip https://data.mos.ru/odata/export/catalog?idFile=263870
~$ unzip data.zip
Archive: data.zip
inflating: data-890-2025-01-17.xlsx
~$ ls
data-890-2025-01-17.xlsx data.zip
Для разбора XLSX-файла воспользуемся утилитой in2csv из пакета утилит csvkit [18]. Преобразуем XLSX-файл, извлечённый из ZIP-архива data.zip, в формат CSV. Опция --reset-dimensions утилиты in2csv позволяет обеспечить поддержку XLSX-таблиц, созданных в приложениях, не сохраняющих в файл с таблицей такие метаданные, как фактическое число строк и столбцов в таблице. Ограничим результат преобразования, выведенный в stdout, первыми 3 строками при помощи утилиты head:
~$ in2csv --reset-dimensions data-890-2025-01-17.xlsx | head -n 3
<frozen importlib._bootstrap>:914: ImportWarning: _SixMetaPathImporter.find_spec() not found; falling back to find_module()
...
При работе утилиты in2csv в стандартный вывод ошибок (stderr) [8] был напечатан ряд диагностических сообщений. Содержимое stderr можно перенаправить в специальный файл /dev/null для игнорирования диагностических сообщений при помощи перенаправления вывода > с указанием дескриптора 2, связанного с stderr:
~$ in2csv --reset-dimensions data-890-2025-01-17.xlsx 2>/dev/null | head -n 3
global_id,ObjectName,NameSummer,PhotoSummer,AdmArea,District,Address,Email,WebSite,HelpPhone,HelpPhoneExtension,WorkingHoursSummer,ClarificationOfWorkingHoursSummer,HasEquipmentRental,EquipmentRentalComments,HasTechService,TechServiceComments,HasDressingRoom,HasEatery,HasToilet,HasWifi,HasCashMachine,HasFirstAidPost,HasMusic,UsagePeriodSummer,DimensionsSummer,Lighting,...
global_id,Название спортивного объекта,Название спортивной зоны ...
2721621929,Бассейн плавательный Московской академии фигурного ...
Из содержимого stdout следует, что первые 2 строки в XLSX-файле содержат заголовки столбцов таблицы на английском и русском языках. При этом названия бассейнов приводятся во 2-м столбце с именем ObjectName, а сведения о размерах бассейнов – в 26-м столбце с именем DimensionsSummer. Передав опцию --skip-lines можно указать утилите in2csv, что при преобразовании XLSX-таблицы в CSV необходимо пропустить первые 2 строки с заголовками столбцов:
~$ in2csv --skip-lines 2 --reset-dimensions data-890-2025-01-17.xlsx 2>/dev/null |
head -n 3
2721621929,Бассейн плавательный Московской академии фигурного катания на коньках,"Бассейн плавательный крытый, нестандартного размера","Photo:b96a1334-8eff-4030-9aaa-5754599e9ea3
",Северо-Восточный административный округ,район Южное Медведково,"Заповедная улица, дом 1",mmpa@mossport.ru,mmpa.mossport.ru,(499) 790-30-77,k,"DayOfWeek:понедельник
Теперь воспользуемся утилитой csvcut из пакета csvkit [18], чтобы исключить из полученной таблицы в формате CSV все строки, кроме 2-й, содержащей названия бассейнов, и 26-й, содержащей сведения о размерах бассейнов:
~$ in2csv --skip-lines 2 --reset-dimensions data-890-2025-01-17.xlsx 2>/dev/null |
csvcut -c 2,26 | head -n 7
Бассейн плавательный Московской академии фигурного катания на коньках,"Square:132.8
Length:16.6
Width:8
Depth:
"
"Спортивный комплекс «Косино», д.8А","Square:400
Опция -c утилиты csvcut позволяет указать через запятую номера тех столбцов, которые необходимо оставить в stdout. Полученный вывод теперь состоит всего из 2 столбцов, но при этом содержимое ячеек и 1-го столбца, и 2-го столбца может включать в себя как символ переноса строки на новую \n, так и запятую. Эти символы используются в формате CSV по умолчанию: символ \n разделяет строки, а запятая разделяет столбцы. В случае, если ячейка таблицы содержит разделитель, значение ячейки обрамляется двойными кавычками, как показано в выводе утилиты in2csv выше. Длина бассейна указана напротив строки Length: во втором столбце.
При помощи утилиты csvformat заменим разделители строк и столбцов CSV с символов переноса строки и запятой на символ @ и точку с запятой соответственно. Убедимся, что в выводе теперь отсутствуют двойные кавычки:
~$ in2csv --skip-lines 2 --reset-dimensions data-890-2025-01-17.xlsx 2>/dev/null |
csvcut -c 2,26 | csvformat -M '@' -D ';' | head -n 7
Бассейн плавательный Московской академии фигурного катания на коньках;Square:132.8
Length:16.6
Width:8
Depth:
@Спортивный комплекс «Косино», д.8А;Square:400
Length:25
При помощи утилиты tr заменим @ на символ переноса строки на новую \n, а символ \n заменим на пробел. Теперь в выводе команды все сведения о бассейне расположены на одной строке – это позволит в дальнейшем воспользоваться инструментами построчной обработки данных:
~$ in2csv --skip-lines 2 --reset-dimensions data-890-2025-01-17.xlsx 2>/dev/null |
csvcut -c 2,26 | csvformat -M '@' -D ';' | tr '@\n' '\n ' | head -n 3
Бассейн плавательный Московской академии фигурного катания на коньках;Square:132.8 Length:16.6 Width:8 Depth:
Спортивный комплекс «Косино», д.8А;Square:400 Length:25 Width:16 Depth:2.2
Бассейн плавательный «ЦСиО Самбо-70 отделение Юность»;Square:128 Length:16 Width:8 Depth:
При помощи утилиты sed в расширенном режиме с поддержкой регулярных выражений извлечём из каждой строки название бассейна и длину бассейна. Расширенный режим sed включается опцией -E:
~$ in2csv --skip-lines 2 --reset-dimensions data-890-2025-01-17.xlsx 2>/dev/null |
csvcut -c 2,26 | csvformat -M '@' -D ';' | tr '@\n' '\n ' |
sed -E 's/(.+);.*Length:([0-9.]+).*/\1;\2/' | head -n 3
Бассейн плавательный Московской академии фигурного катания на коньках;16.6
Спортивный комплекс «Косино», д.8А;25
Бассейн плавательный «ЦСиО Самбо-70 отделение Юность»;16
Указанный в аргументах команды sed после s/ фрагмент регулярного выражения [21] (.+); распознаёт от 1 до \(\infty\) любых символов, стоящих перед точкой с запятой, и добавляет распознанные символы в первую группу за счёт использования круглых скобок впервые в регулярном выражении, после чего пропускается символ ;. Затем правило .*Length: пропускает от 0 до \(\infty\) любых символов, предшествующих строке Length:, также пропускается сама строка Length:. После этого правилом ([0-9.]+) распознаётся и добавляется во вторую группу последовательность, содержащая от 1 до \(\infty\) символов цифр или символа точки, за счёт повторного использования круглых скобок в регулярном выражении. Наконец, пропускается от 0 до \(\infty\) любых оставшихся символов – этому правилу соответствует шаблон .*.
Ссылка на первую группу в секции замены sed указывается как \1, а ссылка на вторую группу – как \2. Таким образом, выражение \1;\2 указывает, что результатом замены, выполняемой утилитой sed, должно стать название бассейна, разделитель в виде символа точки с запятой, и длина бассейна.
При помощи программы на языке AWK добавим к таблице заголовок и оставим в выводе только те бассейны, длина которых превышает 25 метров. Преобразуем таблицу в понятное человеку представление при помощи утилиты csvlook [18]:
~$ in2csv --skip-lines 2 --reset-dimensions data-890-2025-01-17.xlsx 2>/dev/null |
csvcut -c 2,26 | csvformat -M '@' -D ';' | tr '@\n' '\n ' |
sed -E 's/(.+);.*Length:([0-9.]+).*/\1;\2/' |
awk -F ';' 'BEGIN {print "Бассейн;Длина"} $2 > 25 {print}' |
csvlook --max-column-width 50
| Бассейн | Длина |
| -------------------------------------------------- | ----- |
| Спортивный комплекс «Косино», д.8Б | 50,0 |
| Спортивный комплекс «Луч» (плавательный бассейн) | 25,7 |
| Многофункциональный спортивный комплекс «Формул... | 50,0 |
| Спортивный комплекс высшего учебного заведения | 29,3 |
| Физкультурно-оздоровительный комплекс с бассейн... | 50,0 |
| Дворец спорта «Москвич» | 50,0 |
| Спортивный комплекс «Баланс» | 39,0 |
| Спортивный комплекс «Акватория ЗИЛ» | 50,0 |
| Центр современного пятиборья «Северный» | 50,0 |
В awk после однократного выполнения инструкции, указанной в фигурных скобках сразу за ключевым словом BEGIN, для каждой строки вычисляется выражение $2 > 25, где $2 обозначает номер колонки. В качестве разделителя колонок используется аргумент опции -F утилиты awk – точка с запятой. В случае, если выражение $2 > 25 истинно, выполняется следующая сразу за ним инструкция в фигурных скобках – в stdout печатается строка CSV-таблицы.
Реализованный конвейер показан на рис. 6:

Белом цветом на рис. 6 выделены стандартные утилиты командной оболочки Linux, серым цветом выделены утилиты in2csv, csvcut, csvformat и csvlook из пакета утилит csvkit [18], который устанавливается отдельно.
1.6.3. Разбор HTML для получения индекса Хирша
Рассмотрим процесс решения практической задачи в командной строке Linux по получению и обработке данных публикационной активности исследователя с целью вычисления его индекса Хирша. Данные для вычисления будем получать из Российской научной электронной библиотеки Elibrary по протоколу HTTP.
Индекс Хирша – это наукометрический показатель, предложенный Jorge E. Hirsch в работе [22] и широко используемый для численной оценки продуктивности учёных или научных групп [23]. Согласно [22], учёный имеет индекс \(h\), если им опубликовано как минимум \(h\) статей, каждая из которых имеет как минимум \(h\) цитирований.
Библиотека Elibrary интегрирована с Российским индексом научного цитирования (РИНЦ) и позволяет получить список публикаций автора через веб-интерфейс, показанный на рис. 7, по уникальному идентификатору автора [24]:
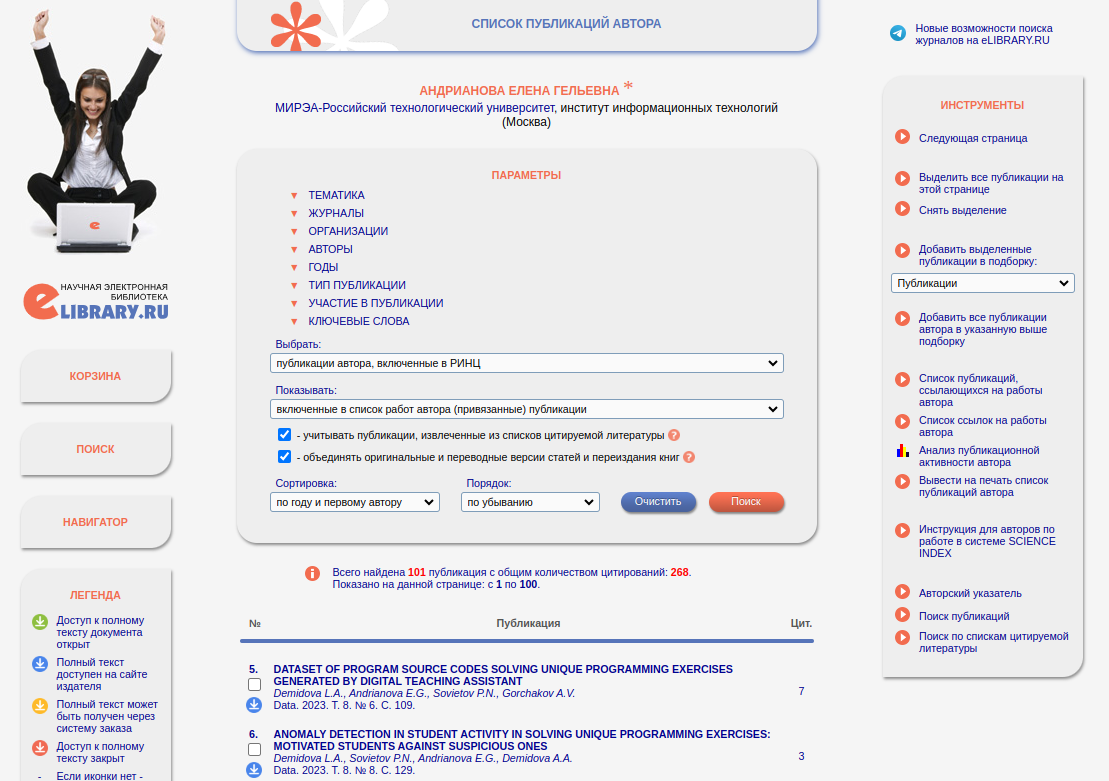
Попробуем получить список публикаций автора с идентификатором 260020 при помощи утилиты curl:
~$ curl -s https://elibrary.ru/author_items.asp?authorid=260020
<head><title>Object moved</title></head>
<body>
<h1>Object Moved</h1>
This object may be found <a href="https://www.elibrary.ru/author_items.asp?authorid=260020">here</a>.
</body>
Утилита curl с опцией -s отправляет GET-запрос на заданный адрес, а опция -s указывает, что не нужно выводить диагностическую информацию. Судя по полученному ответу, веб-сервер Elibrary перенаправляет нас на новый адрес запрашиваемого HTTP-ресурса. Включим обработку HTTP-заголовка location опцией -L для автоматических перенаправлений и снова попытаемся получить список публикаций автора с идентификатором 260020:
~$ curl -s -L https://elibrary.ru/author_items.asp?authorid=260020
<!DOCTYPE html>
<html>
<link rel="stylesheet" href="/style_sm.css" type="text/css" media="screen">
<body>
<div class="midtext">
<img src="/images/error.png" border=0 width=100 height=100 vspace=8><br>
Ошибка в параметрах страницы, <br>или недостаточно прав для открытия страницы.<br>
Уточните запрос или <br>перейдите на <a href="/defaultx.asp">главную страницу сайта</a>
</div>
</body>
</html>
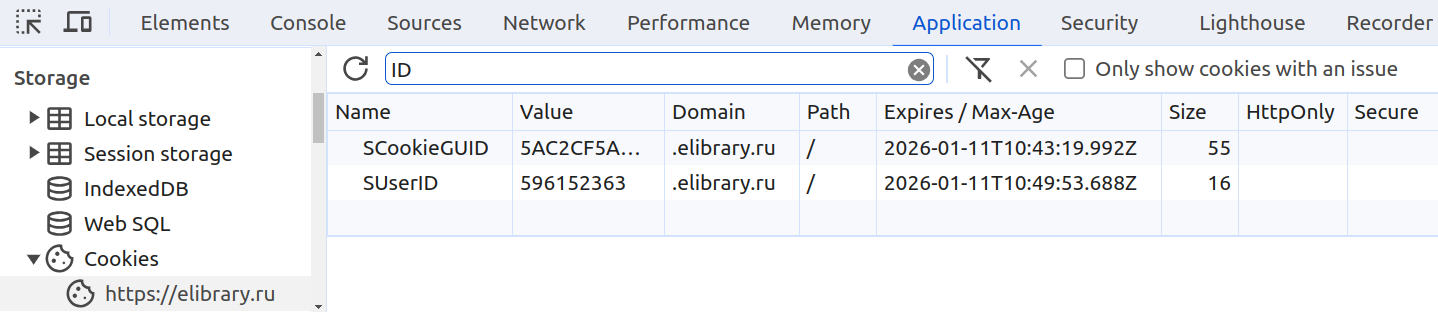
Для загрузки списка публикаций нам необходимо авторизоваться и получить идентификатор сессии Elibrary. Для этого достаточно открыть в веб-браузере ссылку [24], войти на сайт Elibrary, включить инструменты разработчика и извлечь значения SUserID и SCookieGUID из HTTP Cookie для сайта https://www.elibrary.ru. Эти значения будут использоваться в дальнейшем при отправке запросов к Elibrary.
Рассмотрим процесс извлечения идентификатора сессии на примере браузера Google Chrome:
- Выполним вход на сайт Elibrary или зарегистрируем новый аккаунт.
- Откроем страницу со списком публикаций автора 260020 на Elibrary [24].
- Включим инструменты разработчика, нажав клавишу F12.
- В панели инструментов разработчика перейдем на вкладку Application.
- В разделе Storage развернём секцию Cookies и выберем
https://www.elibrary.ru. - Сохраним значения
SUserIDиSCookieGUID(см. рис. 8) для дальнейшего использования.
Вновь попробуем получить список публикаций автора, отправив GET-запрос при помощи curl на адрес [24], но уже с опциями --cookie, значения для которых были получены на предыдущем шаге:
~$ curl -s -L -o author.html --cookie "SCookieGUID=%guid%" --cookie "SUserID=%user%" https://elibrary.ru/author_items.asp?authorid=260020
~$ cat author.html | head -n 5
<!DOCTYPE html>
<html>
<head>
<meta name="robots" content="noindex,nofollow">
Вместо %guid% и %user% необходимо подставить значения HTTP Cookie SCookieGUID и SUserID, полученные из браузера при помощи инструментов разработчика. Опция -o author.html используется, чтобы сохранить ответ сервера в файл author.html вместо вывода в stdout.
В файле author.html теперь находится разметка страницы в формате HTML (Hypertext Markup Language) со сведениями о первых 100 публикациях автора с идентификатором 260020 на Elibrary [24]. Для каждой публикации сохранено её название, сведения об авторах, а также число цитирований. Для вычисления индекса Хирша необходимо разобрать HTML-разметку, сохранённую в файле author.html, и для каждой из публикаций извлечь число её цитирований.
При работе с языками программирования общего назначения для разбора HTML широко используются специализированные инструменты, выполняющие построение объектной модели документа (Document Object Model, DOM), после чего выполняется обход DOM для извлечения необходимых данных. Например, для разбора HTML в Python можно воспользоваться библиотекой BeautifulSoup [25].
Однако, в этом разделе мы намеренно ограничимся только утилитами, доступными в командной оболочке Linux. Сначала убедимся, что в файле author.html действительно 100 статей. Анализируя содержимое файла author.html легко заметить, что сведения о каждой из статей приведены внутри HTML-тега tr с атрибутами valign и id, причём значение атрибута id содержит идентификатор, который может включать в себя как буквы, так и цифры. Воспользуемся утилитами grep и wc для подсчёта строк, содержащих HTML-тег tr с описанными выше атрибутами:
~$ cat author.html | grep -E '<tr valign=middle id="[a-z0-9]+"' | wc -l
100
Опция -E переводит утилиту grep в расширенный режим с поддержкой регулярных выражений, а опция -l указывает, что утилита wc должна подсчитать количество строк.
Теперь, аналогичным образом анализируя HTML-разметку, получим HTML-тег с числом цитирований для каждой из статей, на которую есть хотя бы одна ссылка. Ограничим вывод сведениями о первых 5 статьях:
~$ cat author.html | grep -E 'title="Список статей, ссылающихся на данную">[0-9]+' | head -n 5
<a href="cit_items.asp?gritemid=44028520" title="Список статей, ссылающихся на данную">2</a>
<a href="cit_items.asp?gritemid=37080577" title="Список статей, ссылающихся на данную">50</a>
<a href="cit_items.asp?gritemid=29992112" title="Список статей, ссылающихся на данную">5</a>
<a href="cit_items.asp?gritemid=45625467" title="Список статей, ссылающихся на данную">1</a>
<a href="cit_items.asp?gritemid=61567780" title="Список статей, ссылающихся на данную">1</a>
Добавим к grep в расширенном режиме опцию -o, указывающую, что для каждой строки из stdin, включающей в себя подстроку, соответствующую регулярному выражению title="Список статей, ссылающихся на данную">[0-9]+, необходимо выбрать и вывести в stdout только тот фрагмент, который полностью соответствует регулярному выражению:
~$ cat author.html | grep -E -o 'title="Список статей, ссылающихся на данную">[0-9]+' | head -n 5
title="Список статей, ссылающихся на данную">2
title="Список статей, ссылающихся на данную">50
title="Список статей, ссылающихся на данную">5
title="Список статей, ссылающихся на данную">1
title="Список статей, ссылающихся на данную">1
Упростим регулярное выражение в grep, после чего повторно применим grep для того, чтобы оставить в выводе только число цитирований статей. Затем отсортируем число цитирований по убыванию:
~$ cat author.html | grep -E -o 'данную">[0-9]+' | grep -E -o '[0-9]+' | sort -n -r | head -n 5
50
50
16
14
13
Теперь перейдём к подсчёту индекса Хирша. Поскольку у нас есть отсортированные количества цитирований статей, для подсчёта индекса Хирша воспользуемся следующим алгоритмом: если номер текущей строки меньше или равен значению, расположенному на этой строке, то увеличиваем индекс Хирша на 1.
Этот алгоритм легко реализовать на языке AWK [19]:
~$ cat author.html | grep -Eo 'данную">[0-9]+' | grep -Eo '[0-9]+' | sort -nr | awk 'NR <= $1 { c += 1 } END { print c }'
7
Переменная NR увеличивается в AWK на 1 для каждой прочитанной из stdin строки, а переменная $1 содержит прочитанное значение. Блок { c += 1 } выполняется только в том случае, если условие перед ним истинно. Блок END { print c } выполняется после обработки всех строк из stdin и выводит на экран значение переменной c – вычисленный индекс Хирша.
Полная версия программы на Bash для вычисления индекса Хирша по 100 публикациям на Elibrary имеет вид:
~$ curl -s -L --cookie "SCookieGUID=%guid%" --cookie "SUserID=%user%" \
> https://elibrary.ru/author_items.asp?authorid=260020 \
> | grep -Eo 'данную">[0-9]+' \
> | grep -Eo '[0-9]+' \
> | sort -nr \
> | awk 'NR <= $1 { c += 1 } END { print c }'
7
Реализованный конвейер показан на рис. 9:

Легко вычислить индекс Хирша по 100 публикациям и для другого автора, заменив authorid.
~$ curl -s -L --cookie "SCookieGUID=%guid%" --cookie "SUserID=%user%" \
> https://elibrary.ru/author_items.asp?authorid=499156 \
> | grep -Eo 'данную">[0-9]+' \
> | grep -Eo '[0-9]+' \
> | sort -nr \
> | awk 'NR <= $1 { c += 1 } END { print c }'
8
Если необходимо посчитать индекс Хирша по всем публикациям, то после входа на сайт на странице автора необходимо нажать на ссылку “Вывести на печать список публикаций автора” и разобрать HTML, содержащий все статьи автора, о которых известно научной электронной библиотеке Elibrary:
~$ open https://elibrary.ru/author_items.asp?authorid=499156
Opening in existing browser session.
~$ curl -s --cookie "SCookieGUID=%guid%" --cookie "SUserID=%user%" \
> https://elibrary.ru/author_items_print.asp \
> | grep -Eo "(</td><td align=center valign=top width=30>|<td align=center valign=top>).*</td></tr>" \
> | sed 's/width=30//' \
> | grep -Eo "[0-9]+" \
> | sort -nr \
> | awk 'NR <= $1 { c += 1 } END { print c }'
25
Здесь используется утилита sed, выполняющая поиск подстроки width=30 и её замену на пустую строку.
Реализованный конвейер показан на рис. 10:

1.6.4. Упражнения
Задача 1. Напишите однострочник для получения с помощью GitHub API сообщений всех коммитов заданного репозитория, с сохранением результатов в формате CSV.
Задача 2. Напишите однострочник для получения информации о бассейнах, имеющих ширину более 8 метров.
Задача 3. Напишите однострочник для получения информации о бассейнах, работающих в заданном диапазоне времени.
Задача 4. Доработайте однострочник для получения индекса Хирша таким образом, чтобы не было необходимости открывать страницу автора в браузере перед вычислением индекса Хирша автора по всем публикациям.
Задача 5. Напишите однострочник для вычисления g-индекса заданного автора.