Введение
Что такое конфигурационное управление
Задача управления конфигурацией (configuration management) некоторой системы является типичной для инженерной деятельности. Под конфигурацией понимается состав элементов системы и взаимное их расположение. Конфигурацией можно управлять, отслеживая ее состояние и контролируя целостность изменений конфигурации, а также фиксируя эти изменения в документации.
Можно заметить, что конфигурационное управление в описанном виде представляется достаточно рутинной работой. К счастью, инструменты и подходы, разработанные для конфигурационного управления ПО (software configuration management), позволили автоматизировать многие задачи. Это, в частности, касается популярного инструмента git, который сегодня используется не только программистами, но даже некоторыми художниками и писателями для управления конфигурацией своих творений. Далее под конфигурационным управлением будет пониматься именно конфигурационное управление ПО.
Конфигурационное управление является частью программной инженерии, поэтому к нему применима следующая цитата:
«Программная инженерия – это то, что происходит с программированием при добавлении времени и других программистов» (Russ Cox).
Тематика книги
В этой книге конфигурационное управление трактуется более широко, чем в приведенных выше формальных определениях. Тематика книги в некоторой степени пересекаются с заслуживающими внимания материалами из [1] и [2].
Рассматриваемые далее темы:
- Командная строка.
- Менеджеры пакетов.
- Системы управления версиями.
- Конфигурационные языки.
- Системы автоматизации сборки.
- Виртуальные машины.
- Документация как код.
На рис. 1 приведен граф зависимостей глав книги. Читатель может выбрать собственный порядок изложения тем, не нарушая зависимостей между ними.

Часто можно наблюдать этаких «сапожников без сапог» – программистов, которые решают задачи конечных пользователей, но не занимаются автоматизацией собственных рутинных задач. Поэтому выбор тем книги обусловлен общей целью – стремлением к автоматизации процессов, связанных с разработкой ПО. Акцент на сиюминутных технологиях и инструментах может привести к чрезвычайно быстрому устареванию материала. По этой причине основное внимание в книге уделено общим подходам, алгоритмам и использованию проверенных временем инструментов с открытым кодом.
1.1. Работа в командной строке
1.1. Работа в командной строке
Командная строка на экране монитора – имитация работы с телетайпом. Телетайп, в свою очередь, является электромеханической печатной машиной, которую можно подключить к компьютеру. Пользователь набирает текст, который печатается на рулоне бумаги. Компьютер печатает пользователю свои ответы.
Удивительно, но такой, казалось бы, устаревший способ общения с компьютером все еще активно используется, пусть и с более современными средствами ввода-вывода. Более того, многие задачи очень трудно решить без командной строки! Это касается, в частности, работы с системой контроля версий Git, с системой автоматизации сборки Make, с системой контейнеризации Docker и многими другими популярными сегодня программами. Командная строка в духе UNIX имеется в MacOS, Linux и Windows (WSL, Powershell). Стоит вспомнить и многочисленные фильмы о «хакерах» – если герой фильма решает за компьютером какие-то нетривиальные задачи, то, обычно, зрителю демонстрируется именно командная строка.
Командная строка, как ни странно, хорошо знакома и любителям старых текстовых игр. В этих играх для совершения какого-либо действия необходимо набрать с клавиатуры соответствующую команду в духе go north, read book или take apple.
Вот как выглядит пример диалога с пользователем в игре Zork (1978 г.):
West of House Score: 0 Moves: 4
ZORK
Welcome to ZORK.
Release 13 / Serial number 040826 / Inform v6.14 Library 6/7
West of House
This is an open field west of a white house, with a boarded front door.
There is a small mailbox here.
A rubber mat saying 'Welcome to Zork!' lies by the door.
>open mailbox
You open the mailbox, revealing a small leaflet.
>take leaflet
Taken.
Операционная система UNIX [3] была разработана в далеком 1969 году. UNIX изначально являлась операционной системой в первую очередь для разработчиков, которым удобнее всего автоматизировать свои действия с помощью командной строки. Сама по себе командная строка еще древнее UNIX.
Основная суть решений, принятых при использовании командной строки, сводится к положениям «философии UNIX» (Дуг Макилрой), которые можно выразить следующими пунктами:
- Пусть каждая программа решает одну задачу и решает ее хорошо. Для новых задач создавайте новые программы, а не усложняйте старые новыми «возможностями».
- Предполагайте, что вывод каждой программы может стать входом другой, еще неизвестной программы. Не загромождайте вывод посторонней информацией. Избегайте строго выравненных столбчатых и двоичных входных форматов. Не настаивайте на интерактивном вводе.
- Проектируйте и разрабатывайте ПО, даже операционные системы, таким образом, чтобы его можно было опробовать уже на ранних этапах, в идеале в течение недель. Не бойтесь выбрасывать неудачно реализованные части и пересоздавать их.
- Вместо ручного труда используйте инструменты для облегчения задач разработки, даже если придется отвлечься на создание этих инструментов, а сами инструменты могут впоследствии больше не понадобиться.
Далее будет рассматриваться современный вариант UNIX, популярная ОС Linux, разработанная в 1991 году Линусом Торвальдсом (в то время – студентом финского университета).
При работе с командной строкой необходимо учитывать структуру файловой системы. В Linux она имеет следующий вид:
localhost:~$ tree -d -L 1 /
/
├── bin
├── dev
├── etc
├── home
├── lib
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin
├── srv
├── sys
├── tmp
├── usr
└── var
Имя / является корнем (root) файловой системы. Внутри корня расположены следующие, наиболее значимые каталоги:
- bin. Исполняемые файлы системных утилит.
- dev. Устройства, к которым в Linux возможен доступ, как к файлам.
- etc. Системные конфигурационные файлы.
- home. Домашние каталоги пользователей.
- lib. Системные библиотеки.
- media. Подключаемые съемные диски: USB, CD-ROM и так далее.
- mnt. Подключаемые разделы.
1.2. Командный интерпретатор
1.2. Командный интерпретатор
За поддержку работы в командной строке отвечает специальная программа – интерпретатор оболочки ОС (shell). В случае Linux таким интерпретатором обычно является Bash, архитектура которого приведена на рис. 2. Под Bash далее будем понимать целое семейство работающих схожим образом интерпретаторов. Интерпретатор выполняет следующие основные действия [4]:
- Принимает строку от пользователя.
- Разбирает эту строку и переводит во внутренний формат.
- Осуществляет подстановку для различных специальных символов и имен.
- Выполняет команду пользователя.
- Выдает код выполнения.

Ниже показан пример сеанса работы в Bash:
localhost:~$ pwd
/root
localhost:~$ ls -l
total 16
-rw-r--r-- 1 root root 114 Jul 5 2020 bench.py
-rw-r--r-- 1 root root 76 Jul 3 2020 hello.c
-rw-r--r-- 1 root root 22 Jun 26 2020 hello.js
-rw-r--r-- 1 root root 151 Jul 5 2020 readme.txt
localhost:~$ echo 'new file' > new_file.txt
localhost:~$ cat new_file.txt
new file
localhost:~$ mkdir new_dir
localhost:~$ cp new_file.txt new_dir/
localhost:~$ rm new_file.txt
localhost:~$ ls -l
total 20
-rw-r--r-- 1 root root 114 Jul 5 2020 bench.py
-rw-r--r-- 1 root root 76 Jul 3 2020 hello.c
-rw-r--r-- 1 root root 22 Jun 26 2020 hello.js
drwxr-xr-x 2 root root 66 Nov 4 17:16 new_dir
-rw-r--r-- 1 root root 151 Jul 5 2020 readme.txt
localhost:~$ ls -l new_dir/
total 4
-rw-r--r-- 1 root root 9 Nov 4 17:16 new_file.txt
Обратите внимание на использование в приведенном сеансе команд, упрощенное описание которых дано ниже:
pwd(print working directory). Вывести имя текущего каталога.ls(list). Вывести содержимое каталога.echoВывести свой аргумент.cat(concatenate). Вывести содержимое файла.mkdir(make directory). Создать каталог.cp(copy). Скопировать файл.rm(remove). Удалить файл.
Многие команды имеют ряд аргументов, это, в частности, касается ls, которая выше была вызвана с аргументом -l. Аргументы разделяются пробелами и имеют префикс -.
Узнать об аргументах, которые принимает команда, можно с помощью аргумента --help:
localhost:~$ ls --help
BusyBox v1.31.1 () multi-call binary.
Usage: ls [-1AaCxdLHRFplinshrSXvctu] [-w WIDTH] [FILE]...
List directory contents
-1 One column output
-a Include entries which start with .
-A Like -a, but exclude . and ..
-x List by lines
-d List directory entries instead of contents
-L Follow symlinks
-H Follow symlinks on command line
-R Recurse
-p Append / to dir entries
-F Append indicator (one of */=@|) to entries
-l Long listing format
-i List inode numbers
-n List numeric UIDs and GIDs instead of names
-s List allocated blocks
-lc List ctime
-lu List atime
--full-time List full date and time
-h Human readable sizes (1K 243M 2G)
--group-directories-first
-S Sort by size
-X Sort by extension
-v Sort by version
-t Sort by mtime
-tc Sort by ctime
-tu Sort by atime
-r Reverse sort order
-w N Format N columns wide
--color[={always,never,auto}] Control coloring
Еще одним способом получить подробные сведения о конкретной команде является вызов вида man <команда>.
Без объяснений осталась строка echo 'new file' > new_file.txt в примере сеанса работы в командной строке выше. Здесь используется механизм перенаправления данных с помощью символов < (перенаправление ввода) и > (перенаправление вывода). В Linux имеется источник стандартного ввода stdin (код 0), а также два приемника стандартного вывода: stdout (код 1) и stderr (код 2, для ошибок). Организация ввода/вывода показана на рис. 3.

В примере ниже используется stdout и stderr:
localhost:~$ pwd
/root
localhost:~$ pwd > pwd.txt
localhost:~$ pwd --foo
sh: pwd: illegal option --
localhost:~$ pwd --foo 2> err.txt
localhost:~$ cat err.txt
sh: pwd: illegal option --
Обратите внимание на явное указание кода 2 при сохранении сообщения об ошибке в файл.
Перенаправление ввода/вывода превращается в очень мощную конструкцию при использовании такой организации команд, при которой вывод одной команды попадает на вход другой команды. Эта конструкция представляет собой конвейер и реализуется с помощью символа |, как показано в примере далее:
localhost:~$ pwd > pwd.txt
localhost:~$ rev --help
Usage: rev [options] [file ...]
Reverse lines characterwise.
Options:
-h, --help display this help
-V, --version display version
For more details see rev(1).
localhost:~$ rev pwd.txt
toor/
localhost:~$ pwd | rev
toor/
В Bash имеется удобный синтаксис для развертывания файловых путей (globbing). С помощью символов * (произвольная последовательность) и ? (произвольный символ) реализуется подстановка имен файлов в духе регулярных выражений, как в примере ниже:
localhost:~$ echo *
bench.py err.txt hello.c hello.js new_dir pwd.txt readme.txt rev
localhost:~$ echo *.c
hello.c
localhost:~$ echo p*
pwd.txt
localhost:~$ echo *.??
bench.py hello.js
В Bash есть возможность задать переменные и, кроме того, имеется ряд уже определенных переменных. Обратите внимание на особенности создания переменных:
localhost:~$ A = 42
sh: A: not found
localhost:~$ A=42
localhost:~$ A
sh: A: not found
localhost:~$ echo $A
42
С помощью команды set можно, помимо прочего, узнать, какие переменные сейчас заданы для текущего пользователя:
localhost:~$ set
A='42'
HISTFILE='/root/.ash_history'
HOME='/root'
HOSTNAME='localhost'
IFS='
'
LINENO=''
OLDPWD='/'
OPTIND='1'
PAGER='less'
PATH='/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin'
PPID='1'
PS1='\h:\w\$ '
PS2='> '
PS4='+ '
PWD='/root'
SHLVL='3'
TERM='linux'
TZ='UTC-03:00'
_='/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin'
script='/etc/profile.d/*.sh'
Особенно важна здесь переменная PATH, которая определяет те пути (разделенные с помощью :), где будет осуществляться поиск команд интерпретатором.
Linux является многопользовательской ОС и информация о зарегистрированных пользователях находится в конфигурационном файле /etc/passwd:
localhost:~$ whoami
root
localhost:~$ cat /etc/passwd
root:x:0:0:root:/root:/bin/ash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/mail:/sbin/nologin
news:x:9:13:news:/usr/lib/news:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucppublic:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
man:x:13:15:man:/usr/man:/sbin/nologin
postmaster:x:14:12:postmaster:/var/mail:/sbin/nologin
cron:x:16:16:cron:/var/spool/cron:/sbin/nologin
ftp:x:21:21::/var/lib/ftp:/sbin/nologin
sshd:x:22:22:sshd:/dev/null:/sbin/nologin
at:x:25:25:at:/var/spool/cron/atjobs:/sbin/nologin
squid:x:31:31:Squid:/var/cache/squid:/sbin/nologin
xfs:x:33:33:X Font Server:/etc/X11/fs:/sbin/nologin
games:x:35:35:games:/usr/games:/sbin/nologin
cyrus:x:85:12::/usr/cyrus:/sbin/nologin
vpopmail:x:89:89::/var/vpopmail:/sbin/nologin
ntp:x:123:123:NTP:/var/empty:/sbin/nologin
smmsp:x:209:209:smmsp:/var/spool/mqueue:/sbin/nologin
guest:x:405:100:guest:/dev/null:/sbin/nologin
nobody:x:65534:65534:nobody:/:/sbin/nologin
dhcp:x:100:101:dhcp:/var/lib/dhcp:/sbin/nologin
svn:x:101:102:svn:/var/svn:/sbin/nologin
Информация о каждом из пользователей занимает отдельную строку. Строка разделяется символом : на поля. Первое поле означает имя пользователя. В нашем случае это root. Последнее поле указывает путь к интерпретатору оболочки ОС. В нашем случае это компактный Bash-подобный интерпретатор ash.
Вспомним, как выглядит вывод команды ls в long-формате:
localhost:~$ ls -l
total 20
-rw-r--r-- 1 root root 114 Jul 5 2020 bench.py
drwxr-xr-x 2 root root 37 Nov 4 18:01 foo
-rw-r--r-- 1 root root 76 Jul 3 2020 hello.c
-rw-r--r-- 1 root root 22 Jun 26 2020 hello.js
-rw-r--r-- 1 root root 151 Jul 5 2020 readme.txt
Первый столбец определяет права доступа и информацию о файле (-) или каталоге (d, как в случае с foo), закодированную в первом символе. Флаги доступа бывают следующих основных видов:
-Доступ запрещен.r(read). Имеется доступ на чтение.w(write). Имеется доступ на запись.x(execute). Имеется доступ на исполнение (на вход в случае каталога).
Рассмотрим детали на примере с файлом bench.py, который имеет следующие права доступа:
-rw-r--r-- 1 root root 114 Jul 5 2020 bench.py
|[-][-][-] [----] [----]
| | | | | |
| | | | | +-------------> 6. Группа
| | | | +---------------------> 5. Владелец
| | | |
| | | +----------------------------> 4. Права всех остальных
| | +-------------------------------> 3. Права группы
| +----------------------------------> 2. Права владельца
+------------------------------------> 1. Тип файла
При создании пользовательских команд необходимо указать права на исполнение, как показано в примере ниже:
localhost:~$ echo "ls -l" > lsl
localhost:~$ lsl
sh: lsl: not found
localhost:~$ ./lsl
sh: ./lsl: Permission denied
localhost:~$ chmod +x lsl
localhost:~$ ./lsl
total 24
-rw-r--r-- 1 root root 114 Jul 5 2020 bench.py
drwxr-xr-x 2 root root 37 Nov 4 18:01 foo
-rw-r--r-- 1 root root 76 Jul 3 2020 hello.c
-rw-r--r-- 1 root root 22 Jun 26 2020 hello.js
-rwxr-xr-x 1 root root 6 Nov 4 18:44 lsl
-rw-r--r-- 1 root root 151 Jul 5 2020 readme.txt
В Bash существует ряд специальных переменных, в частности:
$0. Путь к запущенной программе.$1, $2, .... Аргументы программы.$#. Количество аргументов программы.$@. Список аргументов программы.$?. Значение результата выполнения программы (0 означает успешное выполнение).
Рассмотрим в качестве примера следующую программу tests.sh:
echo $0
echo $1 $2
echo $#
echo $@
Результат ее выполнения показан далее:
localhost:~$ ./test.sh 1 2 3 4 5
./test.sh
1 2
5
1 2 3 4 5
localhost:~$ echo $?
0
localhost:~$ foo
sh: foo: not found
localhost:~$ echo $?
127
Рассмотрим теперь более сложный пример пользовательской команды. Далее приведен код на языке Bash вычисления факториала:
#!/bin/sh
seq "$1" | xargs echo | tr " " "*" | bc
В первой строке указан интерпретатор, который будет использоваться для исполнения программы. По соглашению, такую строку необходимо всегда указывать первой в пользовательских скриптах. Далее используется ряд новых команд.
Команда seq (sequence) генерирует последовательность чисел:
localhost:~$ seq 5
1
2
3
4
5
Команда xargs (extended arguments) форматирует список из стандартного ввода:
localhost:~$ seq 5 | xargs
1 2 3 4 5
Команда tr (translate) осуществляет замену текстовых фрагментов:
localhost:~$ seq 5 | xargs | tr " " "*"
1*2*3*4*5
Команда bc (basic calculator) представляет собой калькулятор:
localhost:~$ echo "2+2" | bc
4
Для вычислений в Bash можно также использовать скобки специального вида:
localhost:~$ echo $((2 + 2))
4
Для получения результата команды в виде аргумента другой команды можно также использовать скобки специального вида:
localhost:~$ echo "My folder is $(pwd)"
My folder is /root
В Bash имеются возможности полноценного языка программирования. Ниже приведен пример реализации факториала с использованием ветвлений и рекурсии:
#!/bin/sh
if [ "$1" -le 1 ] ; then
echo 1
return
fi
echo $(( $1 * $( ./fact.sh $(( $1 - 1 )) ) ))
Реализация факториала с использованием цикла:
#!/bin/sh
res=1
for i in $(seq 1 "$1"); do
res=$((res * i))
done
echo $res
Существует веб-инструмент ShellCheck [5], которым можно пользоваться для проверки корректности Bash-скриптов.
1.3. Инструменты командной строки
1.3. Инструменты командной строки
Команда grep (globally search for a regular expression and print matching lines) осуществляет поиск по образцу, определяемому регулярным выражением. Команда sed (stream editor) является строчным редактором, но главное ее использование состоит в замене по шаблону, как и в случае grep, заданному регулярным выражением.
В табл. 1 показаны примеры некоторых базовых элементов регулярного выражения.
| Символ | Действие |
|---|---|
| Буквы, числа, некоторые знаки | Обозначают сами себя |
. |
Любой символ |
[множество символов] |
Любой символ из множества |
[^множество символов] |
Любой символ не из множества |
^ |
Начало строки |
$ |
Конец строки |
^ |
Начало строки |
выражение* |
Повторение выражения 0 или более раз |
выражение выражение |
Последовательность из выражений |
Веб-инструмент regex101 [6] может помочь в поэлементном разборе сложных регулярных выражений.
С использованием grep и sed можно создать достаточно сложные схемы обработки данных. В частности, следующий код осуществляет проверку правописания для файла README.md на основе словаря из файла unix-words:
cat README.md | tr A-Z a-z | tr -cs A-Za-z '\n' | sort | uniq | grep -vx -f unix-words >out ; cat out | wc -l | sed 's/$/ mispelled words!/'
Еще более изощренной, чем grep и sed, является команда awk. AWK (по именам авторов – Aho, Weinberger, Kernighan) представляет собой язык программирования для обработки текстовых данных.
Ниже показан пример вывода колонки №5 из данных, предоставленных вызовом ls -l:
localhost:~$ ls -l
total 36
-rw-r--r-- 1 root root 114 Jul 5 2020 bench.py
-rwxr-xr-x 1 root root 51 Nov 4 18:56 fact.sh
-rwxr-xr-x 1 root root 76 Nov 4 19:45 fact2.sh
drwxr-xr-x 2 root root 37 Nov 4 18:01 foo
-rw-r--r-- 1 root root 76 Jul 3 2020 hello.c
-rw-r--r-- 1 root root 22 Jun 26 2020 hello.js
-rwxr-xr-x 1 root root 6 Nov 4 18:44 lsl
-rw-r--r-- 1 root root 151 Jul 5 2020 readme.txt
-rwxr-xr-x 1 root root 36 Nov 4 18:50 test.sh
localhost:~$ ls -l | awk '{ print $5 }'
114
51
76
37
76
22
6
151
36
Средствами awk легко подсчитать общий размер файлов:
localhost:~$ ls -l | awk '{ s += $5 } END { print s }'
569
В заключение рассмотрим пример вывода на экран самой свежей новости с ресурса Hacker News:
#!/bin/sh
N=$(curl -s https://hacker-news.firebaseio.com/v0/topstories.json | jq '.[0]')
curl -s "https://hacker-news.firebaseio.com/v0/item/$N.json" | jq '.["title"]' | cowsay
Вот как выглядит вывод этой программы:
localhost:~$ ./hn.sh
________________________________________
/ "Finishing my first game while working \
\ full-time" /
----------------------------------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
На тему анализа данных в командной строке существует целая книга [7].
1.4. Модель конвейера
1.4. Модель конвейера
Для однонаправленной межпроцессной коммуникации на практике широко применяют перенаправление ввода/вывода и оператор конвейера |, при помощи которого результат работы одного процесса из его стандартного вывода (stdout) перенаправляется в стандартный ввод (stdin) другого процесса [8].
Рассмотрим ряд простых примеров использования конвейера. Например, при помощи утилиты head и оператора конвейера | легко получить первые 2 строки из файла /etc/passwd, содержащего список пользовательских учётных записей в Linux:
~$ cat /etc/passwd | head -n 2
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
Утилита cat направляет содержимое указанного файла в stdout. При помощи оператора конвейера | результат работы cat из stdout направляется в stdin утилиты head, которая, в свою очередь, направляет в stdout только первые 2 полученные строки, после чего завершает выполнение.
Для поиска по образцу можно воспользоваться утилитой grep:
~$ cat /etc/passwd | grep /usr | head -n 2
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
Теперь в вывод включены только те строки, которые содержат заданную подстроку /usr.
Оператор конвейера, помимо командной оболочки Linux, существует и в некоторых языках программирования общего назначения, таких как Elm [9] и F# [10]. Кроме того, в 2021 году рабочей группой TC39 ассоциации по стандартизации Ecma International было предложено добавить поддержку оператора конвейера в новую версию языка JavaScript, используемого для программирования веб-приложений [11].
Модель конвейера несложно реализовать и в Python, используя перегрузку оператора |.
1.4.1. Простая модель конвейера
Сначала попробуем воспроизвести рассмотренный пример работы с конвейером в командной оболочке Linux на Python при помощи цепочки вызовов простых функций, принимающих на вход список строк stdin и возвращающих новый список строк:
def cat(path):
# Получим список строк из файла, доступного по пути path.
with open(path, 'r', encoding='utf-8') as file:
return file.readlines()
def head(n, stdin):
# Воспользуемся срезом для получения n элементов из списка stdin.
return stdin[:n]
def grep(pat, stdin):
# Создадим новый список из строк, содержащих pat.
stdout = []
for line in stdin:
if pat in line:
stout.append(line)
return stdout
stdout = head(2, grep('/usr', cat('/etc/passwd')))
print(*stdout, sep='', end='')
Результатом работы функции cat является список строк. Полученный из файла /etc/passwd список строк подаётся на вход функции grep, которая возвращает только строки, содержащие подстроку /usr. Результат работы функции grep затем подаётся на вход функции head, возвращающей 2 первых элемента списка. Функция print выводит список строк в stdout.
Поместим наш код в файл pipe.py и попробуем запустить программу:
~$ python pipe.py
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
Для добавления поддержки оператора конвейера | в Python реализуем класс Pipe с перегрузкой оператора побитового «или», а также обновим наши функции так, чтобы они не выполняли вычисления в момент их вызова, а возвращали новые функции, которые будут вызваны при применении к экземпляру класса Pipe оператора конвейера | слева:
class Pipe:
def __init__(self, fun):
self.fun = fun
# Переопределим в классе метод __ror__, вызываемый при
# использовании оператора | слева от экземпляра класса Pipe.
def __ror__(self, lhs):
return self.fun(lhs)
def cat(path):
with open(path, 'r', encoding='utf-8') as file:
return file.readlines()
# Обновим реализацию функций head и grep.
def head(n):
def cmd(stdin):
return stdin[:n]
# В момент вызова функции head создадим экземпляр класса Pipe.
# Передадим в него ссылку на локальную функцию cmd.
return Pipe(cmd)
def grep(pat):
def cmd(stdin):
stdout = []
for line in stdin:
if pat in line:
stout.append(line)
return stdout
return Pipe(cmd)
stdout = cat('/etc/passwd') | grep('/usr') | head(2)
print(*stdout, sep='', end='')
Сравним результат работы модели конвейера с командной оболочкой Linux:
~$ cat /etc/passwd | grep /usr | head -n 2
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
~$ python pipe.py
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
Вывод программы совпадает с выводом утилит cat, grep и head, объединённых оператором конвейера в командной оболочке Linux. Расширим полученную модель конвейера, добавив поддержку сортировки с использованием стандартной функции sorted:
sort = Pipe(sorted)
stdout = cat('/etc/passwd') | grep('/usr') | head(3) | sort
print(*stdout, sep='', end='')
Убедимся, что полученная программа работает корректно:
~$ cat /etc/passwd | grep /usr | head -n 3 | sort
bin:x:2:2:bin:/bin:/usr/sbin/nologin
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
~$ python pipe.py
bin:x:2:2:bin:/bin:/usr/sbin/nologin
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
Полученная реализация оператора конвейера для Python, несмотря на простоту и заметное синтаксическое сходство с конвейером из командной оболочки Linux, не лишена недостатков, которые мы попробуем устранить в сопрограммной модели конвейера.
1.4.2. Сопрограммная модель конвейера
В предыдущей реализации модели все функции, которые могут использоваться вместе с конвейером |, должны быть реализованы по приведенному выше шаблону – эти функции обязательно возвращают новый экземпляр класса Pipe, в который передана ссылка на вложенную функцию, выполняющую вычисления.
Кроме того, в Linux выполнение объединенных при помощи конвейера процессов является сопрограммным – при получении данных из stdout первого процесса через stdin второй процесс сразу же начинает их обрабатывать, а в нашей реализации конвейера на Python списки строк обрабатываются функциями сразу целиком, функции выполняются не сопрограммно, а последовательно.
Первое замечание легко исправить, реализовав декоратор [12], позволяющий «превращать» обычные Python-функции в экземпляры класса Pipe, совместимые с оператором |. А для того, чтобы реализовать сопрограммную обработку строк, достаточно работу со списками заменить на работу с генераторами [13] – в этом случае каждая функция, являющаяся частью конвейера, не будет дожидаться обработки списка строк целиком, обработка элементов последовательности будет проводиться по мере получения новой строки от предыдущей функции.
Оставим без изменений определенный ранее класс Pipe с перегрузкой оператора |, добавим декоратор pipe и перепишем функции cat, head и grep, упростив их реализацию:
from itertools import islice
class Pipe:
def __init__(self, fun):
self.fun = fun
def __ror__(self, lhs):
return self.fun(lhs)
# Декоратор pipe, принимающий на вход функцию fun и
# возвращающий новую функцию, «оборачивающую» fun.
def pipe(fun):
def cmd(*args):
def read(stdin):
return fun(stdin, *args)
return Pipe(read)
return cmd
def cat(path):
with open(path, 'r', encoding='utf-8') as file:
for line in file:
yield line
@pipe
def head(stdin, n):
return islice(stdin, n)
@pipe
def grep(stdin, pat):
for line in stdin:
if pat in line:
yield line
sort = Pipe(sorted)
stdout = cat('/etc/passwd') | grep('/usr') | head(3) | sort
print(*stdout, sep='', end='')
Конструкция *args в списке параметров позволяет создать функцию, принимающую на вход произвольное число позиционных аргументов [12]. Функции cat, head и grep теперь возвращают не списки строк, а генераторы. Это достигается за счёт использования внутри каждой из этих функций оператора yield [13]. Реализация функции sort при этом осталась без изменений.
Добавим в нашу модель конвейера поддержку стандартной утилиты командной оболочки Linux tr и воспользуемся новой функцией, чтобы извлечь абсолютные пути из полученного ранее результата анализа файла /etc/passwd:
@pipe
def tr(stdin, old, new):
for line in stdin:
for pt in line.replace(old, new).splitlines(True):
yield pt
stdout = cat('/etc/passwd') | grep('/usr') | head(3) | tr(':', '\n') | grep('/') | sort
print(*stdout, sep='', end='')
Сравним вывод нашей Python-программы с результатами, полученными в командной оболочке Linux:
~$ cat /etc/passwd | grep /usr | head -n 3 | tr ':' '\n' | grep / | sort
/bin
/dev
/usr/sbin
/usr/sbin/nologin
/usr/sbin/nologin
/usr/sbin/nologin
~$ python pipe.py
/bin
/dev
/usr/sbin
/usr/sbin/nologin
/usr/sbin/nologin
/usr/sbin/nologin
1.4.3. Упражнения
Задача 1. Реализуйте поддержку команд uniq, wc, cut, curl.
Задача 2. Добавьте в модельный вариант grep поддержку регулярных выражений и опции -o. В частности, при помощи доработанной версии grep должно быть можно реализовать вывод имён пользователей, как в Linux: cat /etc/passwd | grep -E -o '^[A-Za-z_0-9-]+'
Задача 3. Реализуйте перенаправление ввода/вывода.
Задача 4. Реализуйте поддержку запуска внешних процессов в виде pipe-функций.
Задача 5. Создайте визуализатор конвейера с использованием инструмента Graphviz [14].
1.5. Конвейер на разных языках программирования
1.5. Конвейер на разных языках программирования
Поскольку при использовании конвейера коммуникация между разными процессами осуществляется через stdout и stdin, эти процессы могут быть представлены запущенными программами, написанными на разных языках программирования. Язык реализации при этом может быть как высокоуровневым, таким как, например, Python, так и низкоуровневым, таким как C.
Рассмотрим процесс разработки инструмента для поиска короткого фрагмента текста в больших текстовых файлах. Компоненты инструмента реализуем на разных языках программирования, а коммуникация между компонентами будет осуществляться сопрограммным образом, при помощи конвейера |.
Доступную в bash утилиту cat используем для получения в stdout содержимого заданного текстового файла. Содержимое файла будет передано по конвейеру утилите scan, разные версии которой мы реализуем на языках Python и С. Эта утилита будет выполнять поиск по короткой подстроке и возвращать результат в виде строки в формате JSON (JavaScript Object Notation) [15]. Утилита stats, в свою очередь, будет реализована на языке Python и использована для преобразования результата работы утилиты scan в понятное для человека табличное представление.
Организация ввода-вывода в нашем инструменте будет иметь вид, показанный на рис. 4:

Серым цветом на рис. 4 выделены утилиты, задействованные в конвейере.
Сначала воспользуемся утилитой командной строки Linux cat для получения в stdout строк из файла /var/log/syslog, содержащего сообщения о происходящих в системе событиях [3]. Также подсчитаем число строк в журнале событий:
~$ cat /var/log/syslog | tail -n 3
Jan 18 00:00:26 user-NBD-WXX9 systemd[1]: Started Make remote CUPS printers available locally.
Jan 18 00:00:26 user-NBD-WXX9 systemd[1]: dpkg-db-backup.service: Deactivated successfully.
Jan 18 00:00:26 user-NBD-WXX9 systemd[1]: Finished Daily dpkg database backup service.
~$ cat /var/log/syslog | wc -l
34031
Утилита tail используется для получения последних 3 строк из вывода cat.
1.5.1. Поиск по подстроке на языке Python
Теперь реализуем на Python утилиту scan.py для поиска по подстроке:
import sys
import json
pat = sys.argv[1]
for i, line in enumerate(sys.stdin):
if pat in line:
o = dict(line=i, content=line[:-1])
print(json.dumps(o))
Эта утилита построчно читает стандартный поток ввода stdin, а функция enumerate используется для получения номера прочитанной строки. В том случае, если переданный в качестве параметра командной строки короткий шаблон содержится в прочитанной строке, утилита scan отправляет в stdout строковое представление JSON-объекта, содержащего ключи line и content. Значением для ключа line является номер найденной строки в анализируемом файле. Значением для ключа content является содержимое строки, из которого удалён символ переноса строки на новую \n.
Для проверки работы scan.py попробуем найти подстроку root в файле /var/log/syslog:
~$ cat /var/log/syslog | python scan.py root | tail -n 3
{"line": 33903, "content": "Jan 17 22:30:01 user-NBD-WXX9 CRON[35710]: (root) CMD ([ -x /etc/init.d/anacron ] && if [ ! -d /run/systemd/system ]; then /usr/sbin/invoke-rc.d anacron start >/dev/null; fi)"}
{"line": 33955, "content": "Jan 17 23:17:01 user-NBD-WXX9 CRON[35863]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)"}
{"line": 33972, "content": "Jan 17 23:30:01 user-NBD-WXX9 CRON[35890]: (root) CMD ([ -x /etc/init.d/anacron ] && if [ ! -d /run/systemd/system ]; then /usr/sbin/invoke-rc.d anacron start >/dev/null; fi)"}
При помощи стандартной утилиты time [3] легко выполнить замеры времени выполнения реализованной утилиты по результатам 100 тестовых запусков поиска подстроки root в текстовом файле /var/log/syslog:
~$ time (for i in $(seq 1 100); do (cat /var/log/syslog | python scan.py root > /dev/null); done)
real 0m2,236s
user 0m1,897s
sys 0m0,583s
Команда seq 1 100 генерирует последовательность из 100 целых чисел. Оператор > позволяет перенаправить stdout в специальный файл /dev/null, который удаляет все записанные в него данные.
Попробуем ускорить поиск подстроки в текстовом файле, формируя JSON без создания временного словаря и без использования функции dumps из модуля json стандартной библиотеки языка Python. Обновим содержимое файла scan.py:
import sys
pat = sys.argv[1]
for i, line in enumerate(sys.stdin):
if pat in line:
print(f'{{"line": {i}, "content": "{line[:-1]}"}}')
Убедимся, что поведение утилиты не изменилось, и повторно измерим время её работы:
~$ cat /var/log/syslog | python scan.py root | tail -n 3
{"line": 33903, "content": "Jan 17 22:30:01 user-NBD-WXX9 CRON[35710]: (root) CMD ([ -x /etc/init.d/anacron ] && if [ ! -d /run/systemd/system ]; then /usr/sbin/invoke-rc.d anacron start >/dev/null; fi)"}
{"line": 33955, "content": "Jan 17 23:17:01 user-NBD-WXX9 CRON[35863]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)"}
{"line": 33972, "content": "Jan 17 23:30:01 user-NBD-WXX9 CRON[35890]: (root) CMD ([ -x /etc/init.d/anacron ] && if [ ! -d /run/systemd/system ]; then /usr/sbin/invoke-rc.d anacron start >/dev/null; fi)"}
~$ time (for i in $(seq 1 100); do (cat /var/log/syslog | python scan.py root > /dev/null); done)
real 0m1,668s
user 0m1,393s
sys 0m0,510s
Время выполнения утилиты scan.py снизилось, а результат выполнения не изменился.
1.5.2. Поиск по подстроке на языке C
Попробуем ускорить утилиту, реализовав на языке C сравнение строк как 64-битных целых чисел – в этом случае длина подстроки для поиска будет ограничена 8 символами, но процесс поиска должен ускориться. Создадим файл scan.c со следующим содержимым:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>
#include <assert.h>
#define MAX_LINE 65536
int found(char *line, uint64_t pat, uint64_t mask) {
for (char *p = line; *p; p++) {
if ((*((uint64_t *) p) & mask) == pat) {
return 1;
}
}
return 0;
}
int main(int argc, char **argv) {
char line[MAX_LINE + sizeof(uint64_t)];
assert(argc == 2);
unsigned pat_size = strlen(argv[1]);
assert(pat_size <= sizeof(uint64_t));
uint64_t mask = (-1llu) >> (sizeof(uint64_t) - pat_size) * 8;
uint64_t pat = *((uint64_t *) argv[1]) & mask;
for (int i = 0; fgets(line, MAX_LINE, stdin) != NULL; i++) {
if (found(line, pat, mask)) {
line[strcspn(line, "\n")] = 0;
printf("{\"line\": %d, \"content\": \"%s\"}\n", i, line);
}
}
return 0;
}
В функции main сначала выделяется память для MAX_LINE + 8 символов и вычисляется размер шаблона для поиска – конструкция assert(pat_size <= 8) позволяет убедиться, что указанный пользователем шаблон занимает не более 8 байт, то есть включает в себя не более 8 ASCII-символов. После этого указатель на первый символ строкового шаблона, имеющий тип char*, преобразуется в указатель на беззнаковое целое, занимающее 8 байт – этот указатель имеет тип uint64_t*. На значение, полученное по указателю с типом uint64_t*, при помощи оператора побитового «и» & накладывается маска mask для того, чтобы установить равными 0 те биты, которые не относятся к указанному пользователем шаблону в том случае, если шаблон занимает меньше 8 байт.
Затем запускается цикл обработки строк, получаемых из stdin – чтение строк из стандартного ввода осуществляется при помощи стандартной функции fgets, определённой в заголовочном файле stdio.h. Функция found выполняет быстрый поиск шаблона pat в строке line по методу скользящего окна. Подстроки p, состоящие из 8 символов, сравниваются с шаблоном pat как 64-битные целые числа. В случае совпадения в stdout печатается JSON-строка, содержащая номер найденной строки и её содержимое, как и в версии утилиты, реализованной на языке Python.
Скомпилируем новую утилиту scan.c и проверим её работу:
~$ clang -O3 -o scan scan.c
~$ ls
scan scan.c scan.py
~$ cat /var/log/syslog | ./scan root | tail -n 3
{"line": 33903, "content": "Jan 17 22:30:01 user-NBD-WXX9 CRON[35710]: (root) CMD ([ -x /etc/init.d/anacron ] && if [ ! -d /run/systemd/system ]; then /usr/sbin/invoke-rc.d anacron start >/dev/null; fi)"}
{"line": 33955, "content": "Jan 17 23:17:01 user-NBD-WXX9 CRON[35863]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)"}
{"line": 33972, "content": "Jan 17 23:30:01 user-NBD-WXX9 CRON[35890]: (root) CMD ([ -x /etc/init.d/anacron ] && if [ ! -d /run/systemd/system ]; then /usr/sbin/invoke-rc.d anacron start >/dev/null; fi)"}
$ time (for i in $(seq 1 100); do (cat /var/log/syslog | ./scan root > /dev/null); done)
real 0m0,543s
user 0m0,452s
sys 0m0,321s
Время выполнения утилиты scan.c, реализованной на языке C, в 4 раза ниже, чем время выполнения первой реализации scan.py на языке Python, и в 3 раза ниже, чем время выполнения ускоренной реализации scan.py на языке Python.
1.5.3. Вывод статистики на языке Python
Полученную последовательность найденных строк в формате JSON легко преобразовать в понятное человеку представление при помощи стороннего модуля для Python tabulate, перед использованием модуль tabulate необходимо установить из реестра пакетов PyPI (Python Package Index) [16].
Реализуем утилиту stats.py следующим образом:
import sys
import json
from tabulate import tabulate
print(tabulate([json.loads(line).values() for line in sys.stdin],
headers=['Строка', 'Содержимое'],
maxcolwidths=[None, 50]))
Утилита stats.py читает все строки в формате JSON из stdin, извлекает из JSON-объектов значения, и передаёт на вход функции tabulate сформированный список, содержащий вложенные списки значений. После этого сформированная модулем tabulate [16] таблица выводится в stdout:
~$ cat /var/log/syslog | ./scan root | tail -n 3 | python stats.py
Строка Содержимое
-------- -------------------------------------------------
33903 Jan 17 22:30:01 user-NBD-WXX9 CRON[35710]: (root)
CMD ([ -x /etc/init.d/anacron ] && if [ ! -d
/run/systemd/system ]; then /usr/sbin/invoke-rc.d
anacron start >/dev/null; fi)
33955 Jan 17 23:17:01 user-NBD-WXX9 CRON[35863]: (root)
CMD ( cd / && run-parts --report
/etc/cron.hourly)
33972 Jan 17 23:30:01 user-NBD-WXX9 CRON[35890]: (root)
CMD ([ -x /etc/init.d/anacron ] && if [ ! -d
/run/systemd/system ]; then /usr/sbin/invoke-rc.d
anacron start >/dev/null; fi)
1.5.4. Упражнения
Задача 1. Что будет, если в обрабатываемой с помощью scan строке появится символ двойной кавычки? Исправьте соответствующим образом код.
Задача 2. Замените в конвейере формат JSON на CSV (Comma-Separated Values). Заголовки колонок должны передаваться программе как параметры командной строки.
Задача 3. Сравните производительность scan с вариантом реализации, использующим стандартную функцию strstr.
Задача 4. Почему grep оказывается быстрее scan? Улучшите код scan с использованием POSIX-функции read, чтобы приблизиться к показателям grep.
Задача 5. Реализуйте scan на языке, отличном от Python и C. Составьте таблицу с оценками производительности всех полученных вариантов scan.
1.6. Однострочники для анализа данных
1.6. Однострочники для анализа данных
1.6.1. Разбор JSON для получения статистики из GitHub
Рассмотрим задачу получения сведений о git-репозиториях пользователя GitHub посредством взаимодействия по протоколу HTTP (Hypertext Transfer Protocol) с удалённым API (Application Programming Interface), возвращающим данные в формате JSON [15]. Отправка запросов и разбор ответов сервера будет осуществляться при помощи утилит командной оболочки Linux. Полученные сведения о репозиториях будут включать их имена и число «звёзд», равное количеству пользователей, добавивших репозиторий в список «избранное».
Начнём с получения списка репозиториев пользователя в формате JSON. В GitHub HTTP API настроены лимиты на число запросов в час, поэтому при помощи утилиты curl отправим единственный HTTP-запрос к API и, воспользовавшись оператором перенаправления вывода >, сохраним результат в файл repos.json. Получим список репозиториев, владельцем которых является пользователь GitHub с именем true-grue:
~$ curl -s https://api.github.com/users/true-grue/repos > repos.json
~$ cat repos.json | head -n 5
[
{
"id": 207806577,
"node_id": "MDEwOlJlcG9zaXRvcnkyMDc4MDY1Nzc=",
"name": "algomusic",
Опция -s используется для отключения вывода диагностических сообщений утилиты curl. Файл repos.json теперь содержит массив объектов со сведениями о репозиториях пользователя GitHub true-grue. В вывод, ограниченный первыми 5 строками, включён идентификатор и имя репозитория algomusic.
Для обработки полученного массива объектов со сведениями о репозиториях воспользуемся утилитой jq [17], предназначенной для преобразования строк в формате JSON и для извлечения данных из них. Утилиту jq версии не ниже 1.6 потребуется установить дополнительно при помощи Вашего пакетного менеджера. Начнём с извлечения объектов из массива, содержащегося в файле repos.json:
~$ cat repos.json | jq '.[0]' | head -n 5
{
"id": 207806577,
"node_id": "MDEwOlJlcG9zaXRvcnkyMDc4MDY1Nzc=",
"name": "algomusic",
"full_name": "true-grue/algomusic",
~$ cat repos.json | jq '.[1]' | head -n 5
{
"id": 427108160,
"node_id": "R_kgDOGXUnQA",
"name": "awesome-russian-cs-books",
"full_name": "true-grue/awesome-russian-cs-books",
Выражение .[i] в списке параметров jq используется для получения \(i\)-го элемента из массива JSON-объектов: выражение .[0] позволяет получить первый элемент массива, а выражение .[1] – второй элемент.
Теперь извлечём имена репозиториев из JSON-объектов по ключу name:
~$ cat repos.json | jq '.[0].name'
"algomusic"
~$ cat repos.json | jq '.[1].name'
"awesome-russian-cs-books"
Для извлечения нескольких значений по нескольким ключам можно воспользоваться оператором конвейера | внутри строки запроса jq. В этом случае каждое полученное значение будет размещено на новой строке:
~$ cat repos.json | jq '.[0] | (.name, .stargazers_count)'
"algomusic"
11
~$ cat repos.json | jq '.[1] | (.name, .stargazers_count)'
"awesome-russian-cs-books"
38
Значения из JSON, имеющие строковой тип данных, выведены в stdout с обрамляющими двойными кавычками, а числовые значения выведены без кавычек. В случае, если необходимо соединить значения полей, можно воспользоваться оператором конкатенации строк +, но числа при этом необходимо явно преобразовать в строки при помощи оператора tostring. Кроме того, подобное преобразование легко применить сразу ко всем JSON-объектам в массиве, заменив .[0] на .[]:
~$ cat repos.json | jq '.[] | (.name + " " + (.stargazers_count | tostring))' | head -n 5
"algomusic 11"
"awesome-russian-cs-books 38"
"ayumi 88"
"BytePusher 6"
"code-snippets 3"
Отсортируем полученный перечень репозиториев по их числу «звёзд», равному количеству добавлений репозиториев в список «избранное» пользователями GitHub. Для этого воспользуемся стандартной утилитой sort, предварительно заменив двойные кавычки на пустые строки утилитой sed:
~$ cat repos.json | jq '.[] | (.name + " " + (.stargazers_count | tostring))' | sed 's/"//g' | sort -k 2 -n -r | head -n 5
Compiler-Development 498
kispython 203
ayumi 88
kisscm 84
raddsl 83
Команда s утилиты sed имеет синтаксис s/шаблон/замена/опции, а опция g переключает утилиту sed в режим глобального поиска и замены. С опцией g вместо однократной замены все двойные кавычки заменятся на пустые строки. Опция -k утилиты sort позволяет указать номер колонки, по которому необходимо упорядочить строки, при этом в качестве разделителя колонок используется пробел. Опция -n включает численную сортировку, а опция -r меняет порядок сортировки на обратный.
Преобразуем результат в формат csv, заменив пробел на запятую при помощи утилиты tr, и выведем в stdout таблицу с данными:
~$ cat repos.json | jq '.[] | (.name + " " + (.stargazers_count | tostring))' | sed 's/"//g' | sort -k 2 -n -r | tr ' ' ',' | csvlook -H | head -n 7
| a | b |
| -------------------- | --- |
| Compiler-Development | 498 |
| kispython | 203 |
| ayumi | 88 |
| kisscm | 84 |
| raddsl | 83 |
Для вывода на экран оформленной таблицы мы воспользовались утилитой csvlook из пакета утилит csvkit [18]. Пакет утилит csvkit версии не ниже 2.0.1 потребуется установить дополнительно при системного пакетного менеджера или пакетного менеджера PyPI. Опция -H утилиты csvlook позволяет использовать имена колонок по умолчанию, поскольку наш вывод в формате csv не содержит строки-заголовка. В качестве имён колонок в csvlook с опцией -H используются буквы английского алфавита.
Добавим строку-заголовок к выводу в формате csv при помощи AWK [19]:
~$ cat repos.json | jq '.[] | (.name + " " + (.stargazers_count | tostring))' | sed 's/"//g' | sort -k 2 -n -r | tr ' ' ',' | awk 'BEGIN { print "Репозиторий,Звёзд" } { print }' | csvlook | head -n 7
| Репозиторий | Звёзд |
| -------------------- | ----- |
| Compiler-Development | 498 |
| kispython | 203 |
| ayumi | 88 |
| kisscm | 84 |
| raddsl | 83 |
В языке AWK инструкция в фигурных скобках, указанная после ключевого слова BEGIN, выполняется однократно в момент начала выполнения команды, и в результате в вывод попадает строка Репозиторий,Звёзд. Инструкция print, указанная следующей также в фигурных скобках, выполняется для каждой строки, поступившей на вход утилите awk через stdin.
Полученный набор команд, объединённых оператором конвейера |, можно упростить, возвращая несколько строк после разбора JSON утилитой jq и объединяя полученные пары строк в одну утилитой xargs со значением параметра -n, равным 2. В случае, если утилита jq вызывается с опцией необработанного вывода -r, нет необходимости в преобразовании типов данных функцией tostring и в удалении двойных кавычек – в stdout значения полей name и stargazers_count попадут как строки, не обрамлённые кавычками. Кроме того, заменять символ пробела на запятую при формировании csv можно прямо в программе на языке AWK, без задействования утилиты tr. Объединим все инструкции в один конвейер:
~$ curl -s https://api.github.com/users/true-grue/repos \
> | jq -r '.[] | (.name, .stargazers_count)' \
> | xargs -n 2 \
> | sort -nrk2 \
> | awk 'BEGIN { print "Репозиторий,Звёзд" } { print $1 "," $2 }' \
> | csvlook \
> | head -n 7
| Репозиторий | Звёзд |
| -------------------- | ----- |
| Compiler-Development | 498 |
| kispython | 203 |
| ayumi | 88 |
| kisscm | 84 |
| raddsl | 83 |
В приведённом примере кода символ \ используется для игнорирования служебного символа переноса строки \n. Это позволяет разбивать на несколько строк длинные команды, в которых разные утилиты объединяются в одну команду при помощи оператора конвейера |.
При помощи реализованного конвейера легко получить статистику по репозиториям другого пользователя, заменив имя пользователя true-grue в ссылке, являющейся параметром утилиты curl. Попробуем в таком же формате вывести сведения о репозиториях, к которым имеет доступ пользователь GitHub worldbeater – такой фильтр можно включить, установив параметр строки запроса type равным значению member. Переносить фрагменты команды на новую строку можно и без использования символа \, как в предыдущем примере – достаточно закончить строку оператором конвейера |:
~$ curl -s https://api.github.com/users/worldbeater/repos?type=member |
jq -r '.[] | (.name, .stargazers_count)' |
xargs -n 2 |
sort -nrk2 |
awk 'BEGIN { print "Репозиторий,Звёзд" } { print $1 "," $2 }' |
csvlook |
head -n 7
| Репозиторий | Звёзд |
| --------------------- | ----- |
| Camelotia | 567 |
| Citrus.Avalonia | 565 |
| Live.Avalonia | 409 |
| ReactiveUI.Validation | 245 |
| ReactiveMvvm | 180 |
Реализованный конвейер показан на рис. 5:

Белом цветом на рис. 5 выделены стандартные утилиты командной оболочки Linux, серым цветом выделены утилиты jq [17] и csvlook [18], которые были установлены отдельно при помощи пакетного менеджера.
1.6.2. Разбор XLSX для поиска бассейнов
В этом разделе рассмотрим задачу обработки табличных данных в формате XLSX (Excel Spreadsheet), полученных из Портала открытых данных Правительства Москвы [20] и содержащих сведения о крытых плавательных бассейнах города, для поиска бассейнов длиной более 25 метров. Начнем с экспорта данных в формате XLSX со страницы [20]. Загрузить данные со страницы [20] можно, нажав на кнопку «экспорт» и выбрав предпочтительный формат или воспользовавшись утилитой curl, указав через опцию -o имя файла, в который необходимо сохранить загруженный ZIP-архив с таблицей:
~$ curl -s -o data.zip https://data.mos.ru/odata/export/catalog?idFile=263870
~$ unzip data.zip
Archive: data.zip
inflating: data-890-2025-01-17.xlsx
~$ ls
data-890-2025-01-17.xlsx data.zip
Для разбора XLSX-файла воспользуемся утилитой in2csv из пакета утилит csvkit [18]. Преобразуем XLSX-файл, извлечённый из ZIP-архива data.zip, в формат CSV. Опция --reset-dimensions утилиты in2csv позволяет обеспечить поддержку XLSX-таблиц, созданных в приложениях, не сохраняющих в файл с таблицей такие метаданные, как фактическое число строк и столбцов в таблице. Ограничим результат преобразования, выведенный в stdout, первыми 3 строками при помощи утилиты head:
~$ in2csv --reset-dimensions data-890-2025-01-17.xlsx | head -n 3
<frozen importlib._bootstrap>:914: ImportWarning: _SixMetaPathImporter.find_spec() not found; falling back to find_module()
...
При работе утилиты in2csv в стандартный вывод ошибок (stderr) [8] был напечатан ряд диагностических сообщений. Содержимое stderr можно перенаправить в специальный файл /dev/null для игнорирования диагностических сообщений при помощи перенаправления вывода > с указанием дескриптора 2, связанного с stderr:
~$ in2csv --reset-dimensions data-890-2025-01-17.xlsx 2>/dev/null | head -n 3
global_id,ObjectName,NameSummer,PhotoSummer,AdmArea,District,Address,Email,WebSite,HelpPhone,HelpPhoneExtension,WorkingHoursSummer,ClarificationOfWorkingHoursSummer,HasEquipmentRental,EquipmentRentalComments,HasTechService,TechServiceComments,HasDressingRoom,HasEatery,HasToilet,HasWifi,HasCashMachine,HasFirstAidPost,HasMusic,UsagePeriodSummer,DimensionsSummer,Lighting,...
global_id,Название спортивного объекта,Название спортивной зоны ...
2721621929,Бассейн плавательный Московской академии фигурного ...
Из содержимого stdout следует, что первые 2 строки в XLSX-файле содержат заголовки столбцов таблицы на английском и русском языках. При этом названия бассейнов приводятся во 2-м столбце с именем ObjectName, а сведения о размерах бассейнов – в 26-м столбце с именем DimensionsSummer. Передав опцию --skip-lines можно указать утилите in2csv, что при преобразовании XLSX-таблицы в CSV необходимо пропустить первые 2 строки с заголовками столбцов:
~$ in2csv --skip-lines 2 --reset-dimensions data-890-2025-01-17.xlsx 2>/dev/null |
head -n 3
2721621929,Бассейн плавательный Московской академии фигурного катания на коньках,"Бассейн плавательный крытый, нестандартного размера","Photo:b96a1334-8eff-4030-9aaa-5754599e9ea3
",Северо-Восточный административный округ,район Южное Медведково,"Заповедная улица, дом 1",mmpa@mossport.ru,mmpa.mossport.ru,(499) 790-30-77,k,"DayOfWeek:понедельник
Теперь воспользуемся утилитой csvcut из пакета csvkit [18], чтобы исключить из полученной таблицы в формате CSV все строки, кроме 2-й, содержащей названия бассейнов, и 26-й, содержащей сведения о размерах бассейнов:
~$ in2csv --skip-lines 2 --reset-dimensions data-890-2025-01-17.xlsx 2>/dev/null |
csvcut -c 2,26 | head -n 7
Бассейн плавательный Московской академии фигурного катания на коньках,"Square:132.8
Length:16.6
Width:8
Depth:
"
"Спортивный комплекс «Косино», д.8А","Square:400
Опция -c утилиты csvcut позволяет указать через запятую номера тех столбцов, которые необходимо оставить в stdout. Полученный вывод теперь состоит всего из 2 столбцов, но при этом содержимое ячеек и 1-го столбца, и 2-го столбца может включать в себя как символ переноса строки на новую \n, так и запятую. Эти символы используются в формате CSV по умолчанию: символ \n разделяет строки, а запятая разделяет столбцы. В случае, если ячейка таблицы содержит разделитель, значение ячейки обрамляется двойными кавычками, как показано в выводе утилиты in2csv выше. Длина бассейна указана напротив строки Length: во втором столбце.
При помощи утилиты csvformat заменим разделители строк и столбцов CSV с символов переноса строки и запятой на символ @ и точку с запятой соответственно. Убедимся, что в выводе теперь отсутствуют двойные кавычки:
~$ in2csv --skip-lines 2 --reset-dimensions data-890-2025-01-17.xlsx 2>/dev/null |
csvcut -c 2,26 | csvformat -M '@' -D ';' | head -n 7
Бассейн плавательный Московской академии фигурного катания на коньках;Square:132.8
Length:16.6
Width:8
Depth:
@Спортивный комплекс «Косино», д.8А;Square:400
Length:25
При помощи утилиты tr заменим @ на символ переноса строки на новую \n, а символ \n заменим на пробел. Теперь в выводе команды все сведения о бассейне расположены на одной строке – это позволит в дальнейшем воспользоваться инструментами построчной обработки данных:
~$ in2csv --skip-lines 2 --reset-dimensions data-890-2025-01-17.xlsx 2>/dev/null |
csvcut -c 2,26 | csvformat -M '@' -D ';' | tr '@\n' '\n ' | head -n 3
Бассейн плавательный Московской академии фигурного катания на коньках;Square:132.8 Length:16.6 Width:8 Depth:
Спортивный комплекс «Косино», д.8А;Square:400 Length:25 Width:16 Depth:2.2
Бассейн плавательный «ЦСиО Самбо-70 отделение Юность»;Square:128 Length:16 Width:8 Depth:
При помощи утилиты sed в расширенном режиме с поддержкой регулярных выражений извлечём из каждой строки название бассейна и длину бассейна. Расширенный режим sed включается опцией -E:
~$ in2csv --skip-lines 2 --reset-dimensions data-890-2025-01-17.xlsx 2>/dev/null |
csvcut -c 2,26 | csvformat -M '@' -D ';' | tr '@\n' '\n ' |
sed -E 's/(.+);.*Length:([0-9.]+).*/\1;\2/' | head -n 3
Бассейн плавательный Московской академии фигурного катания на коньках;16.6
Спортивный комплекс «Косино», д.8А;25
Бассейн плавательный «ЦСиО Самбо-70 отделение Юность»;16
Указанный в аргументах команды sed после s/ фрагмент регулярного выражения [21] (.+); распознаёт от 1 до \(\infty\) любых символов, стоящих перед точкой с запятой, и добавляет распознанные символы в первую группу за счёт использования круглых скобок впервые в регулярном выражении, после чего пропускается символ ;. Затем правило .*Length: пропускает от 0 до \(\infty\) любых символов, предшествующих строке Length:, также пропускается сама строка Length:. После этого правилом ([0-9.]+) распознаётся и добавляется во вторую группу последовательность, содержащая от 1 до \(\infty\) символов цифр или символа точки, за счёт повторного использования круглых скобок в регулярном выражении. Наконец, пропускается от 0 до \(\infty\) любых оставшихся символов – этому правилу соответствует шаблон .*.
Ссылка на первую группу в секции замены sed указывается как \1, а ссылка на вторую группу – как \2. Таким образом, выражение \1;\2 указывает, что результатом замены, выполняемой утилитой sed, должно стать название бассейна, разделитель в виде символа точки с запятой, и длина бассейна.
При помощи программы на языке AWK добавим к таблице заголовок и оставим в выводе только те бассейны, длина которых превышает 25 метров. Преобразуем таблицу в понятное человеку представление при помощи утилиты csvlook [18]:
~$ in2csv --skip-lines 2 --reset-dimensions data-890-2025-01-17.xlsx 2>/dev/null |
csvcut -c 2,26 | csvformat -M '@' -D ';' | tr '@\n' '\n ' |
sed -E 's/(.+);.*Length:([0-9.]+).*/\1;\2/' |
awk -F ';' 'BEGIN {print "Бассейн;Длина"} $2 > 25 {print}' |
csvlook --max-column-width 50
| Бассейн | Длина |
| -------------------------------------------------- | ----- |
| Спортивный комплекс «Косино», д.8Б | 50,0 |
| Спортивный комплекс «Луч» (плавательный бассейн) | 25,7 |
| Многофункциональный спортивный комплекс «Формул... | 50,0 |
| Спортивный комплекс высшего учебного заведения | 29,3 |
| Физкультурно-оздоровительный комплекс с бассейн... | 50,0 |
| Дворец спорта «Москвич» | 50,0 |
| Спортивный комплекс «Баланс» | 39,0 |
| Спортивный комплекс «Акватория ЗИЛ» | 50,0 |
| Центр современного пятиборья «Северный» | 50,0 |
В awk после однократного выполнения инструкции, указанной в фигурных скобках сразу за ключевым словом BEGIN, для каждой строки вычисляется выражение $2 > 25, где $2 обозначает номер колонки. В качестве разделителя колонок используется аргумент опции -F утилиты awk – точка с запятой. В случае, если выражение $2 > 25 истинно, выполняется следующая сразу за ним инструкция в фигурных скобках – в stdout печатается строка CSV-таблицы.
Реализованный конвейер показан на рис. 6:

Белом цветом на рис. 6 выделены стандартные утилиты командной оболочки Linux, серым цветом выделены утилиты in2csv, csvcut, csvformat и csvlook из пакета утилит csvkit [18], который устанавливается отдельно.
1.6.3. Разбор HTML для получения индекса Хирша
Рассмотрим процесс решения практической задачи в командной строке Linux по получению и обработке данных публикационной активности исследователя с целью вычисления его индекса Хирша. Данные для вычисления будем получать из Российской научной электронной библиотеки Elibrary по протоколу HTTP.
Индекс Хирша – это наукометрический показатель, предложенный Jorge E. Hirsch в работе [22] и широко используемый для численной оценки продуктивности учёных или научных групп [23]. Согласно [22], учёный имеет индекс \(h\), если им опубликовано как минимум \(h\) статей, каждая из которых имеет как минимум \(h\) цитирований.
Библиотека Elibrary интегрирована с Российским индексом научного цитирования (РИНЦ) и позволяет получить список публикаций автора через веб-интерфейс, показанный на рис. 7, по уникальному идентификатору автора [24]:
Попробуем получить список публикаций автора с идентификатором 260020 при помощи утилиты curl:
~$ curl -s https://elibrary.ru/author_items.asp?authorid=260020
<head><title>Object moved</title></head>
<body>
<h1>Object Moved</h1>
This object may be found <a href="https://www.elibrary.ru/author_items.asp?authorid=260020">here</a>.
</body>
Утилита curl с опцией -s отправляет GET-запрос на заданный адрес, а опция -s указывает, что не нужно выводить диагностическую информацию. Судя по полученному ответу, веб-сервер Elibrary перенаправляет нас на новый адрес запрашиваемого HTTP-ресурса. Включим обработку HTTP-заголовка location опцией -L для автоматических перенаправлений и снова попытаемся получить список публикаций автора с идентификатором 260020:
~$ curl -s -L https://elibrary.ru/author_items.asp?authorid=260020
<!DOCTYPE html>
<html>
<link rel="stylesheet" href="/style_sm.css" type="text/css" media="screen">
<body>
<div class="midtext">
<img src="/images/error.png" border=0 width=100 height=100 vspace=8><br>
Ошибка в параметрах страницы, <br>или недостаточно прав для открытия страницы.<br>
Уточните запрос или <br>перейдите на <a href="/defaultx.asp">главную страницу сайта</a>
</div>
</body>
</html>
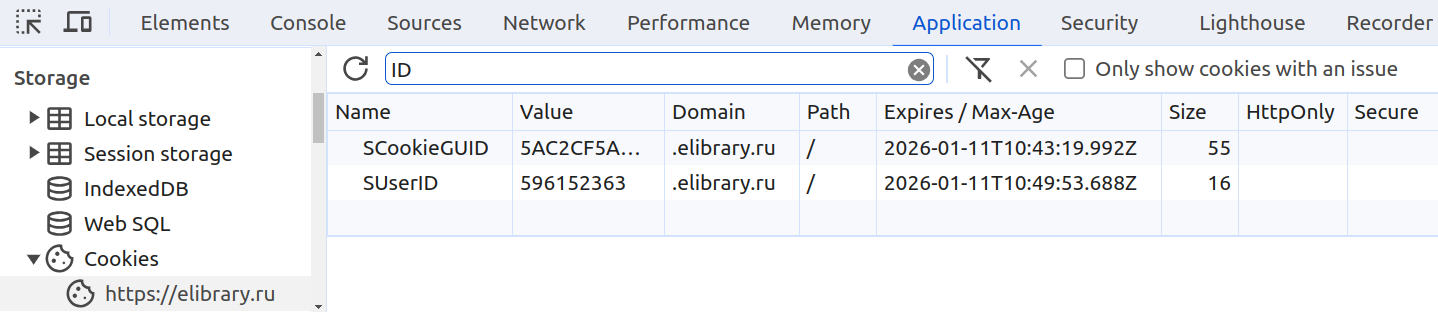
Для загрузки списка публикаций нам необходимо авторизоваться и получить идентификатор сессии Elibrary. Для этого достаточно открыть в веб-браузере ссылку [24], войти на сайт Elibrary, включить инструменты разработчика и извлечь значения SUserID и SCookieGUID из HTTP Cookie для сайта https://www.elibrary.ru. Эти значения будут использоваться в дальнейшем при отправке запросов к Elibrary.
Рассмотрим процесс извлечения идентификатора сессии на примере браузера Google Chrome:
- Выполним вход на сайт Elibrary или зарегистрируем новый аккаунт.
- Откроем страницу со списком публикаций автора 260020 на Elibrary [24].
- Включим инструменты разработчика, нажав клавишу F12.
- В панели инструментов разработчика перейдем на вкладку Application.
- В разделе Storage развернём секцию Cookies и выберем
https://www.elibrary.ru. - Сохраним значения
SUserIDиSCookieGUID(см. рис. 8) для дальнейшего использования.
Вновь попробуем получить список публикаций автора, отправив GET-запрос при помощи curl на адрес [24], но уже с опциями --cookie, значения для которых были получены на предыдущем шаге:
~$ curl -s -L -o author.html --cookie "SCookieGUID=%guid%" --cookie "SUserID=%user%" https://elibrary.ru/author_items.asp?authorid=260020
~$ cat author.html | head -n 5
<!DOCTYPE html>
<html>
<head>
<meta name="robots" content="noindex,nofollow">
Вместо %guid% и %user% необходимо подставить значения HTTP Cookie SCookieGUID и SUserID, полученные из браузера при помощи инструментов разработчика. Опция -o author.html используется, чтобы сохранить ответ сервера в файл author.html вместо вывода в stdout.
В файле author.html теперь находится разметка страницы в формате HTML (Hypertext Markup Language) со сведениями о первых 100 публикациях автора с идентификатором 260020 на Elibrary [24]. Для каждой публикации сохранено её название, сведения об авторах, а также число цитирований. Для вычисления индекса Хирша необходимо разобрать HTML-разметку, сохранённую в файле author.html, и для каждой из публикаций извлечь число её цитирований.
При работе с языками программирования общего назначения для разбора HTML широко используются специализированные инструменты, выполняющие построение объектной модели документа (Document Object Model, DOM), после чего выполняется обход DOM для извлечения необходимых данных. Например, для разбора HTML в Python можно воспользоваться библиотекой BeautifulSoup [25].
Однако, в этом разделе мы намеренно ограничимся только утилитами, доступными в командной оболочке Linux. Сначала убедимся, что в файле author.html действительно 100 статей. Анализируя содержимое файла author.html легко заметить, что сведения о каждой из статей приведены внутри HTML-тега tr с атрибутами valign и id, причём значение атрибута id содержит идентификатор, который может включать в себя как буквы, так и цифры. Воспользуемся утилитами grep и wc для подсчёта строк, содержащих HTML-тег tr с описанными выше атрибутами:
~$ cat author.html | grep -E '<tr valign=middle id="[a-z0-9]+"' | wc -l
100
Опция -E переводит утилиту grep в расширенный режим с поддержкой регулярных выражений, а опция -l указывает, что утилита wc должна подсчитать количество строк.
Теперь, аналогичным образом анализируя HTML-разметку, получим HTML-тег с числом цитирований для каждой из статей, на которую есть хотя бы одна ссылка. Ограничим вывод сведениями о первых 5 статьях:
~$ cat author.html | grep -E 'title="Список статей, ссылающихся на данную">[0-9]+' | head -n 5
<a href="cit_items.asp?gritemid=44028520" title="Список статей, ссылающихся на данную">2</a>
<a href="cit_items.asp?gritemid=37080577" title="Список статей, ссылающихся на данную">50</a>
<a href="cit_items.asp?gritemid=29992112" title="Список статей, ссылающихся на данную">5</a>
<a href="cit_items.asp?gritemid=45625467" title="Список статей, ссылающихся на данную">1</a>
<a href="cit_items.asp?gritemid=61567780" title="Список статей, ссылающихся на данную">1</a>
Добавим к grep в расширенном режиме опцию -o, указывающую, что для каждой строки из stdin, включающей в себя подстроку, соответствующую регулярному выражению title="Список статей, ссылающихся на данную">[0-9]+, необходимо выбрать и вывести в stdout только тот фрагмент, который полностью соответствует регулярному выражению:
~$ cat author.html | grep -E -o 'title="Список статей, ссылающихся на данную">[0-9]+' | head -n 5
title="Список статей, ссылающихся на данную">2
title="Список статей, ссылающихся на данную">50
title="Список статей, ссылающихся на данную">5
title="Список статей, ссылающихся на данную">1
title="Список статей, ссылающихся на данную">1
Упростим регулярное выражение в grep, после чего повторно применим grep для того, чтобы оставить в выводе только число цитирований статей. Затем отсортируем число цитирований по убыванию:
~$ cat author.html | grep -E -o 'данную">[0-9]+' | grep -E -o '[0-9]+' | sort -n -r | head -n 5
50
50
16
14
13
Теперь перейдём к подсчёту индекса Хирша. Поскольку у нас есть отсортированные количества цитирований статей, для подсчёта индекса Хирша воспользуемся следующим алгоритмом: если номер текущей строки меньше или равен значению, расположенному на этой строке, то увеличиваем индекс Хирша на 1.
Этот алгоритм легко реализовать на языке AWK [19]:
~$ cat author.html | grep -Eo 'данную">[0-9]+' | grep -Eo '[0-9]+' | sort -nr | awk 'NR <= $1 { c += 1 } END { print c }'
7
Переменная NR увеличивается в AWK на 1 для каждой прочитанной из stdin строки, а переменная $1 содержит прочитанное значение. Блок { c += 1 } выполняется только в том случае, если условие перед ним истинно. Блок END { print c } выполняется после обработки всех строк из stdin и выводит на экран значение переменной c – вычисленный индекс Хирша.
Полная версия программы на Bash для вычисления индекса Хирша по 100 публикациям на Elibrary имеет вид:
~$ curl -s -L --cookie "SCookieGUID=%guid%" --cookie "SUserID=%user%" \
> https://elibrary.ru/author_items.asp?authorid=260020 \
> | grep -Eo 'данную">[0-9]+' \
> | grep -Eo '[0-9]+' \
> | sort -nr \
> | awk 'NR <= $1 { c += 1 } END { print c }'
7
Реализованный конвейер показан на рис. 9:

Легко вычислить индекс Хирша по 100 публикациям и для другого автора, заменив authorid.
~$ curl -s -L --cookie "SCookieGUID=%guid%" --cookie "SUserID=%user%" \
> https://elibrary.ru/author_items.asp?authorid=499156 \
> | grep -Eo 'данную">[0-9]+' \
> | grep -Eo '[0-9]+' \
> | sort -nr \
> | awk 'NR <= $1 { c += 1 } END { print c }'
8
Если необходимо посчитать индекс Хирша по всем публикациям, то после входа на сайт на странице автора необходимо нажать на ссылку “Вывести на печать список публикаций автора” и разобрать HTML, содержащий все статьи автора, о которых известно научной электронной библиотеке Elibrary:
~$ open https://elibrary.ru/author_items.asp?authorid=499156
Opening in existing browser session.
~$ curl -s --cookie "SCookieGUID=%guid%" --cookie "SUserID=%user%" \
> https://elibrary.ru/author_items_print.asp \
> | grep -Eo "(</td><td align=center valign=top width=30>|<td align=center valign=top>).*</td></tr>" \
> | sed 's/width=30//' \
> | grep -Eo "[0-9]+" \
> | sort -nr \
> | awk 'NR <= $1 { c += 1 } END { print c }'
25
Здесь используется утилита sed, выполняющая поиск подстроки width=30 и её замену на пустую строку.
Реализованный конвейер показан на рис. 10:

1.6.4. Упражнения
Задача 1. Напишите однострочник для получения с помощью GitHub API сообщений всех коммитов заданного репозитория, с сохранением результатов в формате CSV.
Задача 2. Напишите однострочник для получения информации о бассейнах, имеющих ширину более 8 метров.
Задача 3. Напишите однострочник для получения информации о бассейнах, работающих в заданном диапазоне времени.
Задача 4. Доработайте однострочник для получения индекса Хирша таким образом, чтобы не было необходимости открывать страницу автора в браузере перед вычислением индекса Хирша автора по всем публикациям.
Задача 5. Напишите однострочник для вычисления g-индекса заданного автора.
1.7. Эмулятор командной оболочки Linux
1.7. Эмулятор командной оболочки Linux
В этом разделе рассмотрим процесс разработки эмулятора командной оболочки Linux на языке программирования Python. В нашем эмуляторе будут поддерживаться как простые команды, так и команды для работы с виртуальной файловой системой.
1.7.1. Простые команды
Начнём с заготовки эмулятора с поддержкой команд echo, date, exit [8], работающей в режиме REPL (Read-Eval-Print Loop, цикл «чтение – вычисление – вывод»). Перед тем, как приступить к разработке эмулятора, изучим, как работают перечисленные команды в командной оболочке Linux:
~$ echo Hello, world!
Hello, world!
~$ date
Пн 13 янв 2025 02:22:54 MSK
~$ exit
Команда echo печатает в stdout введённый пользователем текст, date позволяет получить текущую дату и время, а exit завершает выполнение процесса командной оболочки.
Создадим файл emu.py и поместим в него код, выполняющий эмуляцию указанных команд:
import time
def repl():
while True:
match input('> ').split():
case ('exit',):
return
case ('echo', *args):
print(*args)
case ('date',):
print(time.asctime())
repl()
При выполнении программы emu.py запускается бесконечный цикл while, на каждой итерации которого демонстрируется приглашение к вводу >. Команда, введённая пользователем в stdin, при помощи метода split разделяется по пробельным символам на отдельные слова.
Для распознавания команд используется структурное сопоставление с образцом [26]. Первое слово, встречающееся во введённой пользователем команде, считается её именем, а все последующие слова – аргументами. Команда exit позволяет выйти из бесконечного цикла, команда echo печатает введённые пользователем аргументы, а команда date печатает текущее время.
Сеанс работы с нашим эмулятором сейчас выглядит так:
~$ python emu.py
> echo Hello, world!
Hello, world!
> date
Mon Jan 13 02:28:33 2025
> echo Bye, world!
Bye, world!
> exit
1.7.2. Виртуальная файловая система
Теперь добавим в эмулятор поддержку работы с виртуальной файловой системой. Сначала ограничимся отображением текущей директории в приглашении к вводу и поддержкой команд cd и pwd. Простой сеанс работы с файловой системой из командной оболочки Linux может иметь вид:
~$ mkdir repo
~$ cd repo
~/repo$ mkdir src
~/repo$ cd src
~/repo/src$ pwd
/home/user/repo/src
~/repo/src$ cd ..
~/repo$ cd ..
~$ cd unknown
bash: cd: unknown: No such file or directory
~$ rm -r repo
Команда mkdir создаёт пустую папку с указанным именем, а при помощи команды cd можно изменить текущую директорию на указанную пользователем. Директория, в которой находится пользователь, отображается в приглашении к вводу [8]. Например, команда cd repo меняет текущую директорию с ~ на ~/repo, и приглашение к вводу имеет вид ~/repo$ вместо ~$. Команда pwd печатает абсолютный путь к текущей директории. Команда cd .. позволяет перейти в родительскую директорию по отношению к текущей директории. При попытке перейти в несуществующую директорию unknown в консоль выводится сообщение об ошибке.
В файловой системе Linux папка содержит только имя для каждого находящегося внутри файла, а также численный указатель на расположение файла, связанный с его именем. Этот численный указатель также известен как индексный дескриптор (inode number) [3]. Структура данных inode, связанная с этим дескриптором, содержит метаданные файла – сведения о файле, за исключением содержащихся в файле данных.
Реализуем в нашем эмуляторе упрощённую модель файловой системы Linux. Создадим класс Node, содержащий сведения о типе файла, а также связанные с файлом данные. Реализуем также команды cd и pwd и подготовим образ виртуальной файловой системы по диаграмме, показанной на рис. 11.

Обновлённая версия нашего эмулятора теперь имеет вид:
class Node:
def __init__(self, file_type, data=''):
self.file_type = file_type
self.data = data
def cd(node, name):
if name in node.data and node.data[name].file_type == 'dir':
return node.data[name]
print('No such file or directory')
return node
def pwd(node):
if par := node.data.get('..'):
for name in par.data:
if par.data[name] == node:
return pwd(par) + name + '/'
return '/'
def repl(node):
while True:
match input(f'{pwd(node)}> ').split():
case ('exit',):
return
case ('cd', name):
node = cd(node, name)
case ('pwd',):
print(pwd(node))
# Реализация команд echo, date.
src = Node('dir', {})
repo = Node('dir', {'src': src})
root = Node('dir', {'repo': repo})
src.data['..'] = repo
repo.data['..'] = root
repl(root)
На вход функции repl передаётся подготовленный образ виртуальной файловой системы. Переменная node в функции repl представляет собой директорию, в которой находится пользователь. В цикл обработки ввода была добавлена поддержка команд cd и pwd, а реализация команд echo и date осталась без изменений.
Новая команда cd в нашем эмуляторе позволяет перемещаться по файловой системе. Если аргументом команды является слово .., текущая директория node меняется на родительскую директорию. Новая команда pwd позволяет получить путь к текущей директории, в качестве разделителя фрагментов пути используется символ /. Путь к текущей директории также печатается в приглашении к вводу, как в командной оболочке Linux.
Проверим работу обновлённого эмулятора:
~$ python emu.py
/> cd repo
/repo/> cd src
/repo/src/> echo It works!
It works!
/repo/src/> pwd
/repo/src/
/repo/src/> cd ..
/repo/> cd ..
/> cd unknown
No such file or directory
/> exit
Для работы с файловой системой полезно иметь возможность создавать как папки, так и файлы – для этого в командной оболочке Linux используются команды mkdir и touch. Кроме того, нужна возможность просмотра содержимого текущей директории – для этого подойдёт команда ls [8].
Добавим в emu.py поддержку команд mkdir, touch и ls :
def mkdir(node, names):
for name in names:
node.data[name] = Node('dir', {'..': node})
def touch(node, names):
for name in names:
node.data[name] = Node('file')
def ls(node):
for name in sorted(node.data):
if name != '..':
print(name, end=' ')
print()
def repl(node):
while True:
match input(f'{pwd(node)}> ').split():
case ('exit',):
return
case ('mkdir', *names):
mkdir(node, names)
case ('touch', *names):
touch(node, names)
case ('ls',):
ls(node)
# Реализация команд cd, pwd, echo, date.
repl(Node('dir', {}))
Функция ls возвращает имена файлов и папок, находящихся внутри текущей директории node. Команды mkdir и touch в нашем эмуляторе создают пустые папки и файлы с указанными именами. Функция mkdir создаёт объект Node с типом файла dir и ссылкой .. на текущую директорию, а функция touch создаёт объект Node с типом файла file с пустым содержимым.
Проверим работу новых команд mkdir, touch и ls:
~$ python emu.py
/> mkdir repo
/> cd repo
/repo/> mkdir src
/repo/> cd src
/repo/src/> touch hello.js hello.py
/repo/src/> ls
hello.js hello.py
/repo/src/> cd ..
/repo/> touch readme.md
/repo/> ls
src readme.md
/repo/> exit
Несложно добавить в эмулятор поддержку команд cat для вывода содержимого указанных файлов в stdout и rm для удаления файлов. Подготовим образ виртуальной файловой системы, соответствующий диаграмме, показанной на рис. 12.
Обновим код нашего эмулятора:
def cat(node, names):
for name in names:
if node.data[name].file_type == 'file':
print(node.data[name].data)
def rm(node, names):
for name in names:
del node.data[name]
def repl(node):
while True:
match input(f'{pwd(node)}> ').split():
case ('exit',):
return
case ('cat', *names):
cat(node, names)
case ('rm', *names):
rm(node, names)
# Реализация команд ls, mkdir, touch, cd, pwd, echo, date.
src = Node('dir', {
'hello.py': Node('file', 'print("Hello, world!")'),
'hello.js': Node('file', 'console.log("Hello, world!")'),
})
repo = Node('dir', {'readme.md': Node('file', ''), 'src': src})
root = Node('dir', {'repo': repo})
src.data['..'] = repo
repo.data['..'] = root
repl(root)

Проверим, работают ли новые команды:
~$ python emu.py
/> cd repo
/repo/> cd src
/repo/src/> ls
hello.js hello.py
/repo/src/> cat hello.py hello.js
print("Hello, world!")
console.log("Hello, world!")
/repo/src/> cat hello.js hello.py
console.log("Hello, world!")
print("Hello, world!")
/repo/src/> rm hello.js
/repo/src/> ls
hello.py
/repo/src/> exit
1.7.3. Упражнения
Задача 1. Добавьте в реализацию команд cd, mkdir, touch, cat, rm поддержку абсолютных путей.
Задача 2. Реализуйте функцию, которая по заданному пути в файловой системе Linux построит в памяти образ виртуальной файловой системы, совместимый с эмулятором.
Задача 3. Спроектируйте формат хранения данных виртуальной файловой системы и реализуйте инструменты для работы с этим форматом: сохранить файловую систему на диске и загрузить её в память с диска.
Задача 4. Реализуйте команду mount для подключения нескольких файловых систем.
Задача 5. Добавьте в эмулятор перенаправление ввода-вывода. Добавьте в эмулятор команду curl, совместимую с перенаправлением ввода-вывода.
2.1. Нумерация версий ПО
2.1. Нумерация версий ПО
В программе, состоящей из нескольких модулей (программных библиотек, пакетов), подключение этих модулей может происходить следующими способами:
- статическое связывание, которое осуществляется на этапе компиляции;
- динамическое связывание, происходящее на этапе выполнения программы.
Как программа, так и подключаемые к ней модули, обычно существуют в нескольких версиях.
Существуют различные схемы нумерации версий:
- последовательные значения;
- дата выпуска;
- хеш-сумма содержимого;
- различные экзотические схемы (например, последовательные цифры числа \(\pi\) или \(e\)).
Проблема ада зависимостей (dependency hell) состоит в наличии конфликтных ситуаций между зависимостями различных модулей. Например, в системном каталоге библиотек может быть только одна версия библиотеки \(X\), при этом одна программа требует \(X\) в версии \(A\), а другая – в несовместимой с \(A\) версии \(B\).
Для управления зависимостями между модулями необходима строгая и единая система нумерации версий, определяющая совместимые и несовместимые сочетания модулей.
2.1.1. Семантическая нумерация версий
В спецификации SemVer (semantic versioning) версия состоит из следующих основных компонентов (см. рис. 13):
- мажорная часть, означающая несовместимые с предыдущими версиями изменения;
- минорная часть, означающая, добавление обратно совместимой функциональности;
- патч, к которому относятся обратно совместимые исправления ошибок.

Сравнение двух версий осуществляется слева направо, до определения первого расхождения. Таким образом устанавливается порядок между версиями, а также могут быть введены интервалы версий.
С помощью символа ^ указываются совместимый интервал версий. Например ~1.2.3 означает >=1.2.3 и <2.0.0. Символ ~ определяет близкие друг к другу версии. Например ~1.2.3 означает >=1.2.3 и <1.3.0.
2.2. Управление пакетами
2.2. Управление пакетами
Менеджер пакетов предназначен для автоматического управления установкой, настройкой и обновлением специального вида модулей, называемых пакетами.
Менеджеры пакетов бывают следующих видов:
- уровня ОС (например, RPM в Linux);
- уровня языка программирования (например, npm для JavaScript);
- уровня приложения (например, Package Control для редактора Sublime Text, управление плагинами для среды Eclipse).
Пакет содержит в некотором файловом формате программный код и метаданные. К метаданным относятся:
- указание авторства, версии и описание пакета;
- список зависимостей пакета;
- хеш-значение содержимого пакета.
Для хранения пакетов используется репозиторий. Репозитории делятся на локальные, располагающиеся на компьютере пользователя и удаленные, размещаемые на сервере, предназначенном для работы с конкретным менеджером пакетов.
2.2.1. Менеджер пакетов apk
Менеджер пакетов apk входит в дистрибутив Alpine ОС Linux.
Работа c apk осуществляется из командной строки. Для добавления нового пакета необходимо использовать опцию add:
/ # apk add python3
fetch https://dl-cdn.alpinelinux.org/alpine/v3.14/main/x86_64/
APKINDEX.tar.gz
fetch https://dl-cdn.alpinelinux.org/alpine/v3.14/community/x86_64/
APKINDEX.tar.gz
(1/13) Installing libbz2 (1.0.8-r1)
(2/13) Installing expat (2.4.1-r0)
(3/13) Installing libffi (3.3-r2)
(4/13) Installing gdbm (1.19-r0)
(5/13) Installing xz-libs (5.2.5-r0)
(6/13) Installing libgcc (10.3.1_git20210424-r2)
(7/13) Installing libstdc++ (10.3.1_git20210424-r2)
(8/13) Installing mpdecimal (2.5.1-r1)
(9/13) Installing ncurses-terminfo-base (6.2_p20210612-r0)
(10/13) Installing ncurses-libs (6.2_p20210612-r0)
(11/13) Installing readline (8.1.0-r0)
(12/13) Installing sqlite-libs (3.35.5-r0)
(13/13) Installing python3 (3.9.5-r1)
Executing busybox-1.33.1-r3.trigger
OK: 56 MiB in 27 packages
В первую очередь менеджером пакетов были загружены списки доступных пакетов из удаленного репозитория. В архиве APKINDEX.tar.gz можно найти информацию по устанавливаемому пакету и его зависимостям:
C:Q1A2S5Zfy6pdKftVzGVhkE5s9r1f4=
P:python3
V:3.9.5-r1
A:x86_64
S:13405337
I:47747072
T:A high-level scripting language
U:https://www.python.org/
L:PSF-2.0
o:python3
m:Natanael Copa <ncopa@alpinelinux.org>
t:1620852262
c:2d63700fe78744e22c497d2cf7f8610828f00544
D:so:libbz2.so.1 so:libc.musl-x86_64.so.1 so:libcrypto.so.1.1 so:libexpat.so.1 so:libffi.so.7 so:libgdbm.so.6 so:libgdbm_compat.so.4 so:liblzma.so.5 so:libmpdec.so.3 so:libncursesw.so.6 so:libpanelw.so.6 so:libreadline.so.8 so:libsqlite3.so.0 so:libssl.so.1.1 so:libz.so.1
p:so:libpython3.9.so.1.0=1.0 so:libpython3.so=0 cmd:2to3 cmd:2to3-3.9 cmd:pydoc3 cmd:pydoc3.9 cmd:python3 cmd:python3.9 py3.9:README.txt=3.9.5-r1
Здесь P: определяет имя пакета, а V: – его версию. С помощью D: в последних строках определяются зависимости, а с помощью p: – те модули, которые пакет предоставляет после своей установки.
2.2.2. Менеджер пакетов apt
В дистрибутиве Ubuntu ОС Linux используется менеджер пакетов apt.
Для установки пакета используется команда apt с опцией install:
apt install instead
В файле Packages, расположенном на удаленном репозитории, располагается информация о доступных для установке пакетах.
Пакет instead имеет следующее описание:
Package: instead
Architecture: amd64
Version: 3.2.1-1
Priority: optional
Section: universe/games
Origin: Ubuntu
Maintainer: Ubuntu Developers <ubuntu-devel-discuss@lists.ubuntu.com>
Original-Maintainer: Sam Protsenko <joe.skb7@gmail.com>
Bugs: https://bugs.launchpad.net/ubuntu/+filebug
Installed-Size: 527
Depends: libc6 (>= 2.14), libgdk-pixbuf2.0-0 (>= 2.22.0), libglib2.0-0 (>= 2.12.0), libgtk2.0-0 (>= 2.8.0), liblua5.1-0, libsdl2-2.0-0 (>= 2.0.8), libsdl2-image-2.0-0 (>= 2.0.2), libsdl2-mixer-2.0-0 (>= 2.0.2), libsdl2-ttf-2.0-0 (>= 2.0.14), zlib1g (>= 1:1.1.4), instead-data (= 3.2.1-1)
Filename: pool/universe/i/instead/instead_3.2.1-1_amd64.deb
Size: 224840
MD5sum: ae8edb2974cece3ff42ce664bcba8485
SHA1: 8e4f27d806d5822e2364c26b6a77502e6e1aada1
SHA256: f0d20dd6d7e3de3c2981bfe3a6fbab0f0be8ecc7bfd3f71736508bee0fe063df
Homepage: https://instead-hub.github.io/
Description: Simple text adventures/visual novels engine
Description-md5: ef0040d4434ac942fb089e9e171d022f
Как можно заметить, анализируя строку Depends:, помимо системных библиотек пакет instead зависит также от пакета instead-data, у которого также имеется описание:
Package: instead-data
Architecture: all
Version: 3.2.1-1
Priority: optional
Section: universe/games
Source: instead
Origin: Ubuntu
Maintainer: Ubuntu Developers <ubuntu-devel-discuss@lists.ubuntu.com>
Original-Maintainer: Sam Protsenko <joe.skb7@gmail.com>
Bugs: https://bugs.launchpad.net/ubuntu/+filebug
Installed-Size: 4092
Depends: fonts-liberation
Recommends: instead
Filename: pool/universe/i/instead/instead-data_3.2.1-1_all.deb
Size: 3681604
MD5sum: e244752081374392d024ab100648213a
SHA1: b560cbc4118b95b5633be48ed40b679652dc1322
SHA256: 06582dc02515a031297dc7ae2e280795f7052266dbb4aee1e2a8406d132ea2c8
Homepage: https://instead-hub.github.io/
Description: Data files for INSTEAD
Description-md5: abbaa9f2bdb5492dca18ea9558b57a9d
Зависимости пакета instead приведены в графе на рис. 14.

2.2.3. Задача разрешения зависимостей пакетов
Задача разрешения зависимостей, которую решает менеджер пакетов, в общем виде относится к труднорешаемым и может быть определена следующим образом.
Дано:
- Состояние локального репозитория, содержащего уже установленные пакеты.
- Состояние удаленного репозитория, в котором находятся все доступные к установке пакеты.
- Имя устанавливаемого пакета.
Необходимо получить план установки нового пакета с разрешением всех его зависимостей. При этом желателен такой вариант решения, который требует установки минимального числа новых пакетов.
Пример задачи разрешения зависимостей показан на рис. 15. Обратите внимание, что из всех возможных версий пакета menu, менеджеру пакетов необходимо выбрать 1.0.0, иначе не получится разрешить зависимости пакета icons.

Для задачи разрешения зависимостей в менеджерах пакетов сегодня все чаще используются универсальные решатели NP-полных задач: SAT-решатели [27], решатели для задачи программирования в ограничениях [28] и другие [29].
2.3. Граф зависимостей пакетов
2.3. Граф зависимостей пакетов
2.3.1. Загрузка списка пакетов Debian
Менеджер пакетов apt используется для автоматического управления установкой и настройкой пакетов [8] в Debian и в различных дистрибутивах Linux, основанных на Debian, таких как Ubuntu, Kubuntu, Kali Linux [30]. Например, сеанс работы с командной строкой для установки пакета jq может иметь следующий вид:
~$ apt update
Сущ:1 http://ru.archive.ubuntu.com/ubuntu jammy InRelease
Пол:2 http://ru.archive.ubuntu.com/ubuntu jammy-updates InRelease [128 kB]
Пол:4 http://ru.archive.ubuntu.com/ubuntu jammy-backports InRelease [127 kB]
Сущ:6 http://security.ubuntu.com/ubuntu jammy-security InRelease
Получено 255 kB за 0с (515 kB/s)
Чтение списков пакетов… Готово
~$ apt install -y jq | tail -n 7
Подготовка к распаковке …/jq_1.6-2.1ubuntu3_amd64.deb
Распаковывается jq (1.6-2.1ubuntu3)
Настраивается пакет libonig5:amd64 (6.9.7.1-2build1)
Настраивается пакет libjq1:amd64 (1.6-2.1ubuntu3)
Настраивается пакет jq (1.6-2.1ubuntu3)
Обрабатываются триггеры для man-db (2.10.2-1)
Обрабатываются триггеры для libc-bin (2.35-0ubuntu3.8)
~$ apt depends jq
jq
Зависит: libjq1 (= 1.6-2.1ubuntu3)
Зависит: libc6 (>= 2.34)
Команда update пакетного менеджера apt позволяет получить сведения о доступных для установки пакетах из удалённых репозиториев, адреса которых указаны в файле /etc/apt/sources.list, а также в файлах, находящихся внутри папки /etc/apt/sources.list.d. Команда install устанавливает пакет с заданным именем, а опция -y отключает подтверждение установки в интерактивном режиме. При установке пакета из удалённого репозитория загружаются и распаковываются архивы с расширением .deb для устанавливаемого пакета и для всех его зависимостей, если нужные версии этих зависимостей уже не были установлены ранее [30]. Команда depends выводит в stdout список зависимостей пакета.
В этом разделе рассматривается процесс разработки средства построения графа зависимостей для заданного пакета Debian на основе анализа метаданных пакетов в формате Packages.gz.
Начнём с получения списка адресов удалённых репозиториев с пакетами Debian. Получить список адресов можно при помощи конвейера, состоящего из команды cat для чтения содержимого файла /etc/apt/sources.list и всех файлов из папки /etc/apt/sources.list.d, утилиты grep в режиме с поддержкой регулярных выражений для удаления комментариев, утилиты uniq для удаления дубликатов строк:
~$ cat /etc/apt/sources.list /etc/apt/sources.list.d/* |
grep -Eo 'deb.*http[^ ]+' | uniq
deb http://ru.archive.ubuntu.com/ubuntu/
deb http://security.ubuntu.com/ubuntu
Загрузим HTML-страницу по первой из полученных ссылок при помощи curl:
~$ curl -s http://ru.archive.ubuntu.com/ubuntu/ | tr -s ' '
<html>
<head><title>Index of /ubuntu/</title></head>
<body>
<h1>Index of /ubuntu/</h1><hr><pre><a href="../">../</a>
<a href="dists/">dists/</a> 17-Oct-2024 10:07 -
<a href="indices/">indices/</a> 21-Jan-2025 08:00 -
<a href="pool/">pool/</a> 27-Feb-2010 06:30 -
<a href="project/">project/</a> 24-Nov-2024 21:31 -
<a href="ubuntu/">ubuntu/</a> 21-Jan-2025 18:58 -
<a href="ls-lR.gz">ls-lR.gz</a> 21-Jan-2025 08:05 30M
</pre><hr></body>
</html>
Утилита tr с опцией -s позволяет избавиться от повторов переданного в качестве параметра опции символа.
Загруженная HTML-страница содержит ссылки на папки. Пакеты Debian находятся в подкаталогах папки dists, причём для разных дистрибутивов Ubuntu и разных архитектур удалённый репозиторий содержит разные файлы Packages.gz.
Папка dists содержит только папки, имена которых совпадают с кодовыми именами версий дистрибутивов Ubuntu, пакеты для которых предоставляет удалённый репозиторий. Узнать кодовое имя версии дистрибутива Ubuntu и архитектуру системы можно следующим образом:
~$ uname -m
x86_64
~$ cat /etc/os-release | head -n 5
PRETTY_NAME="Ubuntu 22.04.3 LTS"
NAME="Ubuntu"
VERSION_ID="22.04"
VERSION="22.04.3 LTS (Jammy Jellyfish)"
VERSION_CODENAME=jammy
Переместимся в папку jammy:
~$ curl -s -L http://ru.archive.ubuntu.com/ubuntu/dists/jammy | tr -s ' '
<html>
<head><title>Index of /ubuntu/dists/jammy/</title></head>
<body>
<h1>Index of /ubuntu/dists/jammy/</h1><hr><pre><a href="../">../</a>
<a href="by-hash/">by-hash/</a> 15-Oct-2021 12:15 -
<a href="main/">main/</a> 10-Nov-2021 22:59 -
<a href="multiverse/">multiverse/</a> 11-Nov-2021 03:59 -
<a href="restricted/">restricted/</a> 10-Nov-2021 23:13 -
<a href="universe/">universe/</a> 11-Nov-2021 00:23 -
<a href="Contents-amd64.gz">Contents-amd64.gz</a> 21-Apr-2022 04:26 45M
<a href="Contents-i386.gz">Contents-i386.gz</a> 21-Apr-2022 05:56 35M
<a href="InRelease">InRelease</a> 21-Apr-2022 17:16 264K
<a href="Release">Release</a> 21-Apr-2022 17:16 263K
<a href="Release.gpg">Release.gpg</a> 21-Apr-2022 17:16 819
</pre><hr></body>
</html>
Папка main внутри папки jammy содержит пакеты компонентов Ubuntu, поддерживаемые издателем дистрибутива Ubuntu. В папке universe расположены сторонние пакеты, поддерживаемые сообществом разработчиков.
Переместимся в папку main, а затем – в папку binary-amd64, содержащую пакеты Debian, совместимые с архитектурой AMD64. В этой папке находится файл Packages.gz, содержащий метаданные всех пакетов Ubuntu 22.04 LTS jammy, поддерживаемых издателем и совместимых с архитектурой AMD64:
~$ curl -s http://ru.archive.ubuntu.com/ubuntu/dists/jammy/main/binary-amd64/ | tr -s ' '
<html>
<head><title>Index of /ubuntu/dists/jammy/main/binary-amd64/</title></head>
<body>
<h1>Index of /ubuntu/dists/jammy/main/binary-amd64/</h1><hr><pre><a href="../">../</a>
<a href="by-hash/">by-hash/</a> 15-Oct-2021 12:15 -
<a href="Packages.gz">Packages.gz</a> 21-Apr-2022 17:16 2M
<a href="Packages.xz">Packages.xz</a> 21-Apr-2022 17:16 1M
<a href="Release">Release</a> 21-Apr-2022 17:16 95
</pre><hr></body>
</html>
Файлы Packages.gz легко загрузить из удалённого репозитория:
~$ curl -s -o main.gz http://ru.archive.ubuntu.com/ubuntu/dists/jammy/main/binary-amd64/Packages.gz
~$ curl -s -o universe.gz http://ru.archive.ubuntu.com/ubuntu/dists/jammy/universe/binary-amd64/Packages.gz
~$ ls -la
-rw-rw-r-- 1 user user 1792213 янв 21 18:10 main.gz
-rw-rw-r-- 1 user user 17471387 янв 21 18:10 universe.gz
2.3.2. Разбор формата Packages.gz
Распакуем загруженные файлы main.gz и universe.gz при помощи стандартной утилиты gzip:
~$ gzip -d main.gz universe.gz
~$ ls -la
-rw-rw-r-- 1 user user 6779186 янв 21 18:11 main
-rw-rw-r-- 1 user user 64332414 янв 21 18:11 universe
В результате распаковки были получены текстовые файлы main и universe. Файл main содержит метаданные пакетов, поддерживаемых издателем Ubuntu, а файл universe – метаданные пакетов от сторонних разработчиков. В этих файлах в начале блока с описанием каждого пакета приводится его название, указанное после подстроки Package:, а также его метаданные, такие как перечень зависимостей, версия, архитектура:
~$ cat main | head -n 3
Package: accountsservice
Architecture: amd64
Version: 22.07.5-2ubuntu1
~$ cat main | grep 'Package' | head -n 3
Package: accountsservice
Package: acct
Package: acl
~$ cat main | grep 'Depends' | head -n 3
Depends: dbus (>= 1.9.18), libaccountsservice0 (= 22.07.5-2ubuntu1), libc6 (>= 2.34), libglib2.0-0 (>= 2.63.5), libpolkit-gobject-1-0 (>= 0.99)
Pre-Depends: init-system-helpers (>= 1.54~)
Depends: libc6 (>= 2.34), lsb-base
Приступим к реализации средства построения графа зависимостей. Сначала попробуем проанализировать текстовые файлы main и universe и получить структуру данных, содержащую имя пакета и сведения о его зависимостях. Создадим файл deb.py со следующим содержимым:
import re
def load_packages(path):
with open(path, 'r', encoding='utf-8') as file:
for line in file:
if line.startswith('Package:'):
name = line.split()[1]
if re.match(r'(Pre-|)Depends:', line):
yield name, line.strip()
print(*load_packages('main'),
*load_packages('universe'), sep='\n')
В приведённом коде мы открываем на чтение файл по указанному пути и в цикле выполняем построчную обработку содержимого файла. Функция load_packages возвращает генератор [13]. В случае, если встретилась строка, начинающаяся с подстроки Package:, мы извлекаем имя пакета и помещаем его в переменную name. В случае, если встретилась строка, начинающаяся с подстроки Depends: или Pre-Depends:, мы возвращаем имя пакета и строку со сведениями о его зависимостях, после чего продолжаем выполнение цикла.
Воспользуемся deb.py для вывода зависимостей пакетов jq и cowsay:
~$ ls
deb.py main universe
~$ python deb.py | grep -E "'jq'|'cowsay'"
('jq', 'Depends: libjq1 (= 1.6-2.1ubuntu3), libc6 (>= 2.34)')
('cowsay', 'Depends: libtext-charwidth-perl, perl:any')
Наш инструмент уже позволяет получать сведения о прямых зависимостях заданного пакета. Однако, на практике у прямой зависимости могут быть и свои собственные зависимости, которые необходимо установить как для её корректной работы, так и для корректной работы исходного пакета – такие зависимости называют транзитивными. Получение и вывод транзитивных зависимостей в нашем инструменте пока не поддерживается.
Попробуем доработать код и сформировать словарь, в котором ключами являются имена пакетов, а значениями – списки зависимостей пакетов:
import re
def load_packages(path):
packages = {}
with open(path, 'r', encoding='utf-8') as file:
for line in file:
if line.startswith('Package:'):
name = line.split()[1]
packages[name] = set()
elif re.match(r'(Pre-|)Depends:', line):
deps = re.sub(r'(Pre-|)Depends:|:any|,|\||\([^,]+\)', ' ', line)
packages[name] |= set(deps.split())
return packages
packages = load_packages('main') | load_packages('universe')
print(packages)
Теперь в случае, если при построчной обработке содержимого файла в начале строки встречается подстрока Package:, в словарь packages добавляется новый ключ – имя пакета, а значением по этому ключу является пустое множество. В случае, если строка содержит перечень зависимостей, то подстроки Pre-Depends:, Depends:, :any, а также сведения о версиях зависимостей, указанные в круглых скобках, заменяются на пробел, после чего строка разделяется на части по символу пробела. Полученный результат добавляется в множество зависимостей пакета. Запись a |= b в Python эквивалентна записи a = a | b, где оператор | выполняет объединение множеств в том случае, если переменные a и b являются множествами – имеют тип set. На последней строке в примере кода выше оператор | используется для объединения словаря, содержащего сведения о пакетах и их зависимостях из файла main, со словарём, содержащим сведения о пакетах и их зависимостях из файла universe.
Проверим работу обновлённого инструмента:
~$ python deb.py | cut -c 1-275
{'accountsservice': {'libglib2.0-0', 'libaccountsservice0', 'dbus', 'libc6', 'libpolkit-gobject-1-0'}, 'acct': {'libc6', 'init-system-helpers', 'lsb-base'}, 'acl': {'libc6', 'libacl1'}, 'acpi-support': {'acpid'}, 'acpid': {'libc6', 'init-system-helpers', 'kmod', 'lsb-base'},
Утилита cut позволяет ограничить длину выводимой в stdout строки путём задания промежутка выводимых символов при помощи опции -c. В результате работы функции load_packages был построен граф зависимостей packages, представленный в виде словаря dict[str, list[str]], ключ в котором – это имя пакета, а значение – множество смежных с пакетом вершин. Граф включает как пакеты, поддерживаемые издателем Ubuntu (файл main), так и пакеты, поддерживаемые сообществом разработчиков (файл universe).
2.3.3. Визуализация графа в редакторе yEd
Для построения графа зависимостей пакета с заданным именем на основе графа зависимостей всех пакетов packages, полученного по результатам анализа файлов в формате Packages.gz из репозитория ru.archive.ubuntu.com, добавим функцию make_graph в файл deb.py. Кроме того, имя пакета Debian, граф зависимостей которого необходимо построить, будем передавать программе как аргумент командной строки – для получения аргумента командной строки воспользуемся модулем sys:
import sys
def make_graph(root, packages):
def dfs(name):
graph[name] = set()
for dep in packages.get(name, set()):
if dep not in graph:
dfs(dep)
graph[name].add(dep)
graph = {}
dfs(root)
return graph
packages = load_packages('main') | load_packages('universe')
root = sys.argv[1]
graph = make_graph(root, packages)
print(graph)
Функция make_graph принимает на вход имя пакета root и граф зависимостей всех пакетов packages. Вложенная функция dfs обходит граф зависимостей packages в глубину (Depth-First Search, DFS) и выполняет построение нового графа, содержащего только пакет с именем name и его зависимости.
Проверим работу make_graph, построив граф зависимостей для пакета jq:
~$ python deb.py jq
{'jq': {'libc6', 'libjq1'}, 'libc6': {'libcrypt1', 'libgcc-s1'}, 'libcrypt1': {'libc6'}, 'libgcc-s1': {'libc6', 'gcc-12-base'}, 'gcc-12-base': set(), 'libjq1': {'libc6', 'libonig5'}, 'libonig5': {'libc6'}}
Для визуализации графа зависимостей воспользуемся библиотекой с открытым исходным кодом yed.py [31]. Библиотека состоит из единственного файла yed.py и позволяет при помощи языка Python генерировать описание графа в формате graphml, основанном на формате XML (eXtensible Markup Language) [8]. Формат graphml используется в редакторе диаграмм yEd [32] для описания графов.
Установим библиотеку yed.py:
~$ curl -s -o yed.py https://raw.githubusercontent.com/true-grue/yed_py/refs/heads/master/yed.py
~$ ls
deb.py main universe yed.py
Добавим в файл deb.py функцию viz для преобразования графа зависимостей в формат graphml с целью его последующей визуализации в редакторе диаграмм и графов yEd:
import yed
def viz(graph, path):
y = yed.Graph()
nodes = {}
for name in graph:
nodes[name] = y.node(text=name, font_family='Times New Roman',
shape='box', height=25)
for name, deps in graph.items():
for dep in deps:
y.edge(nodes[name], nodes[dep])
y.save(f'{path}.graphml')
packages = load_packages('main') | load_packages('universe')
root = sys.argv[1]
graph = make_graph(root, packages)
viz(graph, root)
Функция viz для ключей словаря graph, представленных именами пакетов, генерирует фрагменты graphml с описанием вершин графа. После этого при повторном обходе словаря graph генерируются связи между каждым пакетом и связанными с ним пакетами. Результат работы функции viz сохраняется в файл, расположенный по пути path.
Проверим работу обновлённого средства для визуализации зависимостей:
~$ python deb.py jq
~$ ls
deb.py jq.graphml main universe yed.py
~$ cat jq.graphml | head -n 10 | tail -n 3
<y:ShapeNode>
<y:Geometry x="0" y="0" width="50" height="50"/>
<y:Fill color="#ffffff"/>
Для того, чтобы визуализировать сгенерированный и сохранённый в файл jq.graphml граф зависимостей, файл jq.graphml необходимо открыть в редакторе yEd [32] и выбрать иерархическую компоновку вершин графа в меню Layout. Результат визуализации графа в редакторе yEd показан на рис. 16.

Серым цветом на рис. 16 показаны циклические зависимости:
- Пакет
libc6зависит отlibgcc-s1, причёмlibgcc-s1также зависит отlibc6. - Пакет
libc6зависит отlibcrypt1, причёмlibcrypt1также зависит отlibc6.
Попробуем исключить из рис. 16 стрелки, выделенные серым цветом, разрывая циклические зависимости при построении графа зависимостей пакета. Заменим в deb.py функцию make_graph на функцию make_dag, оставив без изменений остальной код:
def make_dag(root, packages):
def dfs(name):
graph[name] = set()
for dep in packages.get(name, set()):
if dep not in graph:
dfs(dep)
if dep in seen:
graph[name].add(dep)
seen.add(name)
seen = set()
graph = {}
dfs(root)
return graph
packages = load_packages('main') | load_packages('universe')
root = sys.argv[1]
graph = make_dag(root, packages)
viz(graph, root)
Функция make_dag в процессе обхода исходного графа зависимостей в глубину сохраняет вершины графа в множестве seen после завершения их обработки, при этом связи между вершинами добавляются в граф-результат graph только в том случае, если вершина ещё не была обработана и отсутствует в множестве seen – таким образом удаётся разорвать циклы, которые могут присутствовать в исходном графе. Результатом работы функции make_dag является направленный ациклический граф (Directed Acyclic Graph, DAG).
Повторно сформируем граф зависимостей пакета jq для yEd:
~$ python deb.py jq
~$ ls
deb.py jq.graphml main universe yed.py
Обновлённый результат визуализации графа зависимостей пакета jq, сохранённого в файл jq.graphml, показан на рис. 17. По сравнению с рис. 16, в графе, показанном на рис. 17, отсутствуют циклы.

Попробуем сформировать граф для пакета с большим числом зависимостей:
~$ python deb.py cowsay
~$ ls
cowsay.graphml deb.py jq.graphml main universe yed.py
Результат визуализации cowsay.graphml в редакторе yEd показан на рис. 18.

2.3.4. Упражнения
Задача 1. Измените формат вывода графов зависимостей на язык dot, используемый в Graphviz [14]. Изобразите графы зависимостей для пакетов jq и cowsay.
Задача 2. Реализуйте инструмент командной строки для построения графа зависимостей для разных версий одного и того же пакета Debian, требуемая версия пакета указывается как параметр командной строки.
Задача 3. Реализуйте инструмент командной строки для построения графа зависимостей для одного из менеджеров пакетов, перечисленных в табл. 2, на Ваш выбор. Имя пакета, граф зависимостей которого необходимо построить, и его версия указываются как параметры командной строки.
| Менеджер пакетов | Репозиторий | Формат |
|---|---|---|
| pip | pypi.org/pypi/{name}/json | JSON |
| npm | registry.npmjs.org/{name} | JSON |
| Cargo | crates.io/api/v1/crates/{name}/{version} | JSON |
| Maven | repo1.maven.org/maven2 | XML, pom-файл |
| NuGet | api.nuget.org/v3 | XML |
| apk | dl-cdn.alpinelinux.org/alpine/ | APKINDEX.tar.gz |
| apt | archive.ubuntu.com/ubuntu/ | Packages.gz |
Задача 4. Найдите прикладное ПО (это не должна быть ОС или язык программирования) со встроенным менеджером пакетов. Постройте визуализатор зависимостей между всеми пакетами этого ПО.
Задача 5. При визуализации зависимостей между всеми пакетами репозиториев Debian инструмент визуализации или не справится со своей работой, или же результат окажется совершенно неразборчивым. Придумайте и реализуйте способ производительной и наглядной визуализации графа зависимостей между тысячами пакетов.
2.4. Задача разрешения зависимостей пакетов
2.4. Задача разрешения зависимостей пакетов
2.4.1. SAT- и SMT-решатели
При установке пакета заданной версии необходимо установить все его зависимости – программные библиотеки и прочие файлы, обязательные для корректной работы пакета. Например, для пакета Debian его зависимости представлены другими пакетами Debian, а совместимые версии указаны в файле Packages.gz. Кроме того, у пакета также могут быть транзитивные зависимости – такие пакеты, от которых он зависит неявно, через другие пакеты.
В файлах Packages.gz со списками пакетов из компонентов репозитория Ubuntu main и universe, по результатам анализа которых в предыдущем разделе были построены графы зависимостей, приведены сведения о более 60 000 пакетов. Вследствие этого разрешение зависимостей вручную при установке пакета Debian являлось бы чрезвычайно трудоёмким процессом – ведь помимо построения графа зависимостей необходимо для каждой зависимости устанавливаемого пакета выбрать версию, совместимую и с пакетом, и со всеми его зависимостями, включая транзитивные. Поэтому на практике для разрешения зависимостей используются специализированные инструменты, такие как, например, универсальные решатели NP-полных задач [8].
Задача разрешения зависимостей является NP-полной [33] и может быть сведена к задаче выполнимости булевой формулы (Boolean Satisfiability Problem, SAT). Для решения SAT могут использоваться решатели NP-полных задач, такие как, например, Z3 [34] и MiniZinc [35]. В этом разделе рассмотрим процесс работы с Z3 на примере решения простой задачи выполнимости формул в теориях (Satisfiability Modulo Theories, SMT). В SMT, в отличие от SAT, в формуле могут фигурировать предикаты, оперирующие, например, битовыми векторами.
2.4.2. Пример описания задачи для SMT-решателя
Попробуем с помощью Z3 [34] автоматически решить следующую задачу:
На лужайке находятся фазаны и кролики. Можно рассмотреть всего 9 голов и 24 лапы. Сколько на лужайке кроликов и сколько фазанов?
Заметим, что 9 голов, которые можно рассмотреть по условию задачи, могут принадлежать как кроликам, так и фазанам. Кроме того, известно, что у кролика 4 лапы, а у фазана – 2. Обозначим число кроликов как \(r\), а число фазанов – как \(p\). Тогда условие задачи может быть представлено в виде системы уравнений с целочисленными переменными:
| $$ \begin{cases} r + p = 9,\\ 4r + 2p = 24. \end{cases} $$ | (1) |
Решение для системы уравнений (1) легко найти автоматически при помощи решателя Z3. Установим пакет z3-solver для языка программирования Python при помощи пакетного менеджера PyPI:
~$ pip install z3-solver
Collecting z3-solver
Downloading z3_solver-4.13.4.0-py3-none-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (29.0 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 29.0/29.0 MB 18.0 MB/s eta 0:00:00
Installing collected packages: z3-solver
Successfully installed z3-solver-4.13.4.0
Создадим новый файл solve.py и поместим в него следующий код:
from z3 import *
r = Int("r")
p = Int("p")
s = Solver()
s.add(r + p == 9)
s.add(4 * r + 2 * p == 24)
print(s.check())
print(s.model())
В приведённом коде сначала создаются 2 целочисленные символьные переменные r и p, где r – число кроликов, а p – число фазанов. После этого создаётся экземпляр класса Solver, к которому добавляются ограничения на число голов и число лап, как в составленной выше системе уравнений. Затем выполняется проверка системы уравнений на наличие решений посредством вызова метода check. В случае, если решения существуют, результатом работы check будет константа sat, а в случае отсутствия решений – unsat. При помощи вызова метода model в stdout выводится найденное решение.
Проверим работу программы:
~$ python solve.py
sat
[p = 6, r = 3]
Решение задачи найдено автоматически – 6 фазанов и 3 кролика.
2.4.3. Разрешение зависимостей с помощью SMT-решателя
Теперь рассмотрим пример автоматического разрешения зависимостей при помощи SMT-решателя Z3 [34] для пакета root, граф зависимостей которого показан на рис. 19.
Стрелки, соединяющие пакеты в графе, обозначают факт наличия зависимости одного пакета от другого. В случае, если из одной и той же версии пакета A исходит несколько стрелок, указывающих на разные версии пакета B, то это значит, что пакет А совместим с несколькими версиями пакета B, и необходимо решить, какую версию B следует установить. В рассматриваемой задаче 2 версии одного и того же пакета устанавливать не нужно.
Из графа зависимостей, приведённого на рис. 19, следует, что пакет root версии 1.0.0 совместим с любой из версий пакета menu и только с версией 1.0.0 пакета icons. Это значит, что при установке пакета root обязательна установка любой из версий пакета menu, а также пакета icons версии 1.0.0. Пакет dropdown является транзитивной зависимостью root, поскольку явно root от dropdown не зависит, но каждой из версий пакета menu необходима установка пакета dropdown.

Представим граф, показанный на рис. 19, в виде булевой формулы. Стрелки в графе зависимостей выразим как импликации, а совместимость одного пакета с различными версиями другого пакета укажем при помощи логического «или».
Введём следующие обозначения:
- Пакет
rootобозначим как \(r\). - Пакет
menu– как \(m\). - Пакет
dropdown– как \(d\). - Пакет
icons– как \(i\).
Версию пакета будем указывать справа от его имени, игнорируя номер патч-версии [8], поскольку в графе зависимостей на рис. 19 номер патч-версии всегда равен 0. Например, логическую переменную, обозначающую, следует ли устанавливать пакет root версии 1.0.0, обозначим как \(r_{1.0}\) – такая переменная принимает значение 1 в случае, если пакет следует установить, и 0, если его устанавливать не следует.
Запишем булеву формулу для графа, показанного на рис. 19:
| $$ \begin{align} ( r_{1.0} \implies (m_{1.5} \lor m_{1.4} \lor m_{1.3} \lor m_{1.2} \lor m_{1.1} \lor m_{1.0}) \land i_{1.0}) \land \\ ( m_{1.5} \implies d_{2.3}) \land ( m_{1.4} \implies d_{2.3} \lor d_{2.2}) \land ( m_{1.3} \implies d_{2.2}) \land \\ ( m_{1.2} \implies d_{2.2} \lor d_{2.1}) \land ( m_{1.1} \implies d_{2.2} \lor d_{2.1} \lor d_{2.0}) \land ( m_{1.0} \implies d_{1.8}) \land \\ ( d_{2.3} \implies i_{2.2}) \land ( d_{2.2} \implies i_{2.2}) \land ( d_{2.1} \implies i_{2.2}) \land ( d_{2.0} \implies i_{2.2}) \land \\ r_{1.0}. \end{align} $$ | (2) |
Кроме импликаций, обозначающих, что при установке пакета слева от оператора импликации необходимо установить его зависимости, указанные справа от оператора импликации, в формуле (2) есть последний компонент, обязывающий установить пакет \(r_{1.0}\).
При установке пакета и его зависимостей пакетному менеджеру также необходимо убедиться, что для каждой зависимости установлена только одна из её версий. Это дополнительное правило можно представить в виде SMT-формулы – формулы, в которой логические переменные могут быть заменены предикатами:
| $$ \begin{align} (m_{1.5} + m_{1.4} + m_{1.3} + m_{1.2} + m_{1.1} + m_{1.0} \leq 1) \land \\ (d_{2.3} + d_{2.2} + d_{2.1} + d_{2.0} + d_{1.8} \leq 1) \land \\ (i_{2.0} + i_{1.0} \leq 1) \land \\ (r_{1.0} \leq 1). \end{align} $$ | (3) |
Теперь для разрешения зависимостей необходимо объединить формулы (2) и (3) при помощи логического «и» и найти такие значения переменных, при которых полученная формула выполняется, либо показать, что таких значений нет и, следовательно, задача разрешения зависимостей не имеет решений.
Создадим файл deps.py и поместим в него словарь, ключами в котором являются короткие имена пакетов с указанием их версий, а значениями – списки, содержащие зависимости, сгруппированные по имени пакета. Содержимое словаря соответствует булевой формуле (2) и графу, показанному на рис. 19:
packages = {
'r10': [('m15', 'm14', 'm13', 'm12', 'm11', 'm10'), ('i10',)],
'm15': [('d23',)],
'm14': [('d23', 'd22')],
'm13': [('d22',)],
'm12': [('d22', 'd21')],
'm11': [('d22', 'd21', 'd20')],
'm10': [('d18',)],
'd23': [('i20',)],
'd22': [('i20',)],
'd21': [('i20',)],
'd20': [('i20',)],
'd18': [],
'i10': [],
'i20': [],
}
Дополним файл deps.py и опишем задачу для Z3 [34]:
from z3 import *
from itertools import groupby
var = {name: Bool(name) for name in packages}
s = Solver()
s.add(var['r10'])
for name in packages:
for alts in packages[name]:
s.add(Implies(var[name], Or([var[d] for d in alts])))
for _, versions in groupby(packages, lambda p: p[0]):
s.add(Sum([var[v] for v in versions]) <= 1)
if s.check() == sat:
print(s.model())
Сначала создадим словарь var, связывающий имена пакетов с инициализированными символьными логическими переменными. После этого создадим экземпляр класса решателя Solver и укажем, что пакет root версии 1.0.0 обязателен к установке, как в формуле (2).
Для каждого пакета и его зависимостей из словаря packages сформируем выражения с импликациями по формуле (2), воспользовавшись классами Implies и Or, и добавим сформированные выражения к набору ограничений экземпляра класса Solver при помощи метода add. Затем сгруппируем ключи словаря packages по имени пакета, получив таким образом списки версий, и добавим к набору ограничений решателя компоненты SMT-формулы (3), предварительно создав из списка версий символьную переменную Sum и сравнив её с единицей, единица при этом неявно преобразуется в символьную переменную.
После того, как задача для Z3 полностью описана, проверим при помощи вызова метода check, имеет ли задача решения, и в случае положительного результата выведем найденное решение в stdout. Оставим в stdout только логические переменные со значениями True при помощи утилиты grep:
~$ python deps.py | grep True
r10 = True,
m10 = True,
d18 = True,
i10 = True,
Выделим выбранные решателем версии пакетов на графе зависимостей символом «✓». Результат показан на рис. 20.

Таким образом, SMT-решателем было найдено следующее решение:
- Установить
rootверсии 1.0.0. - Установить
menuверсии 1.0.0. - Установить
dropdownверсии 1.8.0. - Установить
iconsверсии 1.0.0.
2.4.4. Упражнения
Задача 1. Добавьте в реализованную программу для разрешения зависимостей на Z3 дополнительное ограничение с целью проверки, что автоматически найденное решение — единственное. Убедитесь в единственности решения для графа зависимостей, показанного на рис. 19.
Задача 2. Докажите законы де Моргана на Z3.
Задача 3. Решите задачу о расстановке 8 ферзей на Z3.
Задача 4. Используйте язык MiniZinc вместо Z3 для разрешения зависимостей пакетов.
Задача 5. Разработайте инструмент разрешения зависимостей, в котором версии пакетов представлены в формате SemVer.
3.1. Система контроля версий Git
3.1. Система контроля версий Git
Предположим, программист, незнакомый с инструментами контроля версий, хочет внести новое, экспериментальное изменение в свою программу. Наш программист сохраняет текущее состояние программного проекта в отдельном каталоге и далее занимается нововведениями в своем коде. В какой-то момент оказывается, что экспериментальная идея оказалась неудачной и программист восстанавливает состояние проекта из ранее сохраненного каталога. Такой способ управления версиями проекта требует большой дисциплины и ручного труда. Особенно трудоемкой работа с версиями проекта становится в условиях коллективной разработки. Именно эту работу и призвана автоматизировать система контроля версий.
Система контроля версий (СКВ, Version Control System, VCS) – основной инструмент конфигурационного управления, позволяющий управлять изменениями (версиями) в файлах или иных наборах данных.
Коммит (commit) – фиксация факта изменений в СКВ.
Репозиторий (repository, repo) – место хранения данных проекта, управляемого СКВ.
Ветка (branch) – отдельная копия части репозитория, в которую можно вносить изменения, не влияющие на другие ветки.
Различают следующие типы систем контроля версий (СКВ):
- локальные системы;
- централизованные системы;
- распределенные системы.
Локальные СКВ (local VCS) относятся к самым первым системам контроля версий, которые появились еще в начале 70-х. Локальность означает, что история изменений хранится на компьютере пользователя. В локальных СКВ файлы хранятся в виде патчей – изменений между соседними версиями файла (см. утилиту diff в UNIX), что позволяет экономить дисковое пространство. В коллективном режиме пользователи обмениваются между собой (обычно по электронной почте) патчами. Очевидно, что такой подход к коллективной разработке нельзя назвать удобным.
Централизованные СКВ (centralized VCS) используют клиент-серверную архитектуру. СКВ и связанный с ней репозиторий проекта теперь находятся на сервере. Каждый пользователь на своем локальном компьютере имеет только ту часть общего репозитория, с который непосредственно работает. Такой подход упрощает коллективную разработку, однако проблемы с доступом к серверу СКВ могут затруднить работу всего коллектива.
Распределенные СКВ (distributed VCS) отличаются использованием полной копии проекта на каждом из компьютеров пользователя, что обеспечивает лучшую сохранность проекта, чем в случае централизованных СКВ. В распределенных СКВ могут использоваться различные схемы взаимодействия между удаленными репозиториями и, в частности, может моделироваться работа по клиент-серверной модели.
При совместной работе над одними и теми же файлами неизбежно возникают конфликты доступа к данным. В СКВ используются следующие способы разрешения конфликтов:
- блокировка доступа к файлу первым пользователем, который к нему обратился;
- использование локальных копий файла у каждого пользователя с последующим слиянием общих результатов работы в автоматическом или ручном режиме.
В табл. 3 представлены три поколения СКВ.
| Поколение | Модель взаимодействия | Единица операции | Примеры |
|---|---|---|---|
| 1 | Локальная | Файл | SCCS, RCS |
| 2 | Централизованная | Файл / множество файлов | CVS, SourceSafe, Subversion, Team Foundation Server |
| 3 | Распределенная | Множество файлов | Bazaar, Git, Mercurial, Fossil |
История развития СКВ показана на рис. 21.

Git [36] является децентрализованной СКВ. Разработана эта система была Л. Торвальдсом в 2005 году для нужд управления версиями ядра ОС Linux. Сегодня Git является самой популярной СКВ. Работу с Git не назовешь простой и многие пользователи критикуют эту систему за неудобный интерфейс командной строки. Тем не менее, основные архитектурные решения в Git являются изящными и логичными, но для того, чтобы их оценить, необходимо узнать, как работает Git изнутри.
3.1.1. Простейшие команды Git
Рассмотрим сначала самые распространенные команды Git.
Создание Git-репозитория в текущем каталоге:
~$ mkdir my_repo
~$ cd my_repo
~/my_repo$ git init .
Initialized empty Git repository in /root/my_repo/.git/
Состояние git-репозитория:
~/my_repo$ git status
On branch master
No commits yet
nothing to commit (create/copy files and use "git add" to track)
В данном случае Git сообщает очевидное – в проекте еще не было коммитов.
Создадим теперь первый файл в репозитории:
~/my_repo$ echo "# Some text" > readme.md
~/my_repo$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
readme.md
nothing added to commit but untracked files present (use "git add" to track)
Теперь информация о статусе репозитория изменилась – появился неотслеживаемый файл readme.md.
В Git файлы могут находиться в следующих состояниях:
- неотслеживаемые файлы (untracked) – файлы, которые Git не учитывает в своей работе,
- измененные файлы (modified) – отслеживаемые файлы, содержимое которых было изменено, но не добавлено в область индексирования;
- индексированные файлы (staged) – измененные файлы, добавленные в область индексирования;
- зафиксированные файлы (commited) – файлы, добавленные в коммит.
Таким образом, при создании нового коммита сначала нужно добавить выбранные файлы в специальную промежуточную зону – область индексирования.
Проиндексировать файлы можно с помощью команды Git add:
~/my_repo$ git add readme.md
~/my_repo$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: readme.md
После добавления всех необходимых файлов в зону индекса (это можно сделать одной командой: git add .) создается коммит, но если в Git еще не заданы данные пользователя, то необходимо сначала их указать:
~/my_repo$ git config --local user.name "Peter"
~/my_repo$ git config --local user.email "peter@example.com"
~/my_repo$ git commit -m "first commit"
[master (root-commit) 3ba9fa7] first commit
1 file changed, 1 insertion(+)
create mode 100644 readme.md
Теперь первая версия проекта зафиксирована. Информацию о коммитах выдает следующая команда:
~/my_repo$ git log
commit 3ba9fa7980a4ba36086e66389b1ef95cbbf317e2 (HEAD -> master)
Author: Peter <peter@example.com>
Date: Tue Nov 16 17:08:47 2021 +0300
first commit
Обратите внимание на длинную последовательность 3ba9fa.... Это хеш-значение коммита, определяющее текущую версию репозитория. Текущая ветка проекта является главной и традиционно называется master или main.
Работу с версиями в Git можно изобразить в виде графа коммитов, см. рис. 22.

3.1.2. Ветвление в Git
Традиционно ветвление в СКВ позволяет разделять проект на независимые сущности (ветки), где изменения в конкретной ветке не затрагивают остальные ветки. Это полезно в условиях коллективной разработки, когда программисты одновременно работают над разными частями программы. Представим ситуацию, когда есть задача по разработке новой функциональности, но необходимо параллельно вносить и исправления в проект, не затрагивая новые функции. В таких ситуациях используется ветвление: под новые задачи создается отдельная ветка, и разработка ведется в ней.
Рассмотрим на примерах ветвление в Git.
Новая ветка создается с помощью команды git branch имя. Переключиться на ветку можно с помощью git checkout имя. Так как создание ветки и переключение на нее – зачастую следующие друг за другом операции, их можно выполнить одной командой git checkout -b имя.
Предположим, работа над репозиторием my_repo развивалась следующим образом:
git branch tests
git add ...
git commit -m "..."
git checkout tests
git add ...
git commit -m "..."
git add ...
git commit -m "..."
На рис. 23 показано новое состояние графа коммитов репозитория.

В какой-то момент ветки сливаются (merge):
git checkout master
git merge tests
На рис. 24 показан результат этого слияния. Был создан новый коммит, объединяющий в себе изменения из обеих веток.
Так как ветки master и tests указывают на один и тот же коммит, то ветку test, если она больше не нужна, можно удалить командой git branch -d tests.

Еще одним способом объединения веток является перебазирование, осуществляемое командой git rebase:
git checkout master
git rebase tests
На рис. 25 показан результат перебазирования ветки tests на master. Здесь изменения, созданные в tests, были применены поверх master. В результате получена линейная история коммитов, которую, зачастую, изучать проще, чем результат, полученный с помощью merge.

3.1.3. Git изнутри
Все служебную информацию о репозитории Git хранит в подкаталоге .git. Основой Git является таблица объектов, адресуемая по ключам – хеш-значениям этих объектов. Такая схема хранения позволяет автоматически задавать уникальную версию для каждого файла (эта версия определяется ключом в таблице, то есть хеш-значением содержимого файла), а также дает возможность избежать дублирования файлов с одинаковым содержимым.
В Git используются следующие типы объектов:
- blob (binary large object) – содержимое файлов репозитория,
- дерево – текущее состояние или снимок файловой иерархии репозитория,
- коммит – информация о коммите.
На рис. 26 показано более детальное состояние репозитория для примера с перебазированием из предыдущего раздела.

Попробуем найти в нашем тестовом репозитории my_repo (в его состоянии на момент первого коммита) информацию о хеш-значениях веток:
$ cd .git
~/my_repo/.git$ ls
COMMIT_EDITMSG HEAD branches config description hooks index info logs objects refs
~/my_repo/.git$ cd refs
~/my_repo/.git/refs$ ls
heads tags
~/my_repo/.git/refs$ cd heads
~/my_repo/.git/refs/heads$ ls
master
~/my_repo/.git/refs/heads$ cat master
3ba9fa7980a4ba36086e66389b1ef95cbbf317e2
Зная хеш-значение объекта master можно попробовать найти его в таблице объектов:
~/my_repo/.git/refs/heads$ cd ..
~/my_repo/.git/refs$ cd ..
~/my_repo/.git$ cd objects/
~/.git/objects$ ls
07 3b 7d info pack
~/my_repo/.git/objects$ cd 3b
~/my_repo/.git/objects/3b$ ls
a9fa7980a4ba36086e66389b1ef95cbbf317e2
Подкаталоги с числами в objects указывают на начальную часть хеш-значения объекта, сам же файл объекта можно найти соответствующего подкаталога.
Файлы, содержащие объекты внутри objects, хранятся в двоичном формате. Для отображения информации об объекте по его хеш-значению можно использовать следующую команду:
~/my_repo$ git cat-file -p 3ba9fa7980a4ba36086e66389b1ef95cbbf317e2
tree 074f8b59918b080288259854fcf875a6b8e543fe
author Peter <peter@example.com> 1637071727 +0300
committer Peter <peter@example.com> 1637071727 +0300
first commit
Был выдан объект коммита. Объекты этого типа включают в себя:
- хеш-значение связанного с коммитом объекта дерева;
- хеш-значения родителей коммита (в рассматриваемом случае коммит единственный, поэтому информация о его родителях не показана);
- метаданные, в том числе указание авторства и текст коммита.
Попробуем теперь изучить объект дерева по его полученному хеш-значению:
~/my_repo$ git cat-file -p 074f8b59918b080288259854fcf875a6b8e543fe
100644 blob 7dfce3922d94e459d1545a9fc568be0369eaa973 readme.md
В нашем случае файловая иерархия состоит из всего одного файла. Объекты типа дерева включают в себя:
- хеш-значения blob-объектов;
- хеш-значения объектов деревьев;
- указание прав доступа к файлам и каталогам.
Blob-объект для readme.md можно изучить аналогичным образом.
Обратите внимание, что в Git хеш-значение единственного коммита характеризует не только репозиторий на момент совершения коммита, но и всю предшествующую над ним работу. Это достигается благодаря использованию в Git иерархии хеш-значений («хеш-значения от хеш-значений»). Благодаря такой организации данных любые внесенные искажения в репозиторий или в одну из его предыдущих версий могут быть немедленно выявлены.
3.2. Алгоритм diff
3.2. Алгоритм diff
3.2.1. Команда git diff
Важной частью распределённой системы контроля версий (СКВ) git [36] является средство сравнения разных версий изменившегося файла, позволяющее отследить, какие именно фрагменты файла были изменены. В этом разделе рассмотрим команду git diff, а затем реализуем её упрощённый вариант на основе модифицированного расстояния Левенштейна.
Основой git diff является алгоритм, решающий задачу вычисления наибольшей общей подпоследовательности (Longest Common Subsequence, LCS). Известно множество алгоритмов для решения задачи LCS, различающихся по своим характеристикам. В git поддерживаются такие алгоритмы, как Patience, Minimal, Histogram, Myers, причём по умолчанию используется алгоритм Myers [36]. Мы реализуем простейший из diff-алгоритмов, основанный на модифицированном расстоянии Левенштейна, в котором, в отличие от расстояния Левенштейна [37], нет операции замены символа.
Начнём работу с создания нового репозитория, воспользовавшись для этого командой git init, и добавим в созданный репозиторий новый файл fib.py, содержащий функцию для вычисления чисел Фибоначчи, реализованную на языке Python. После этого добавим файл fib.py в область индексирования при помощи команды git add fib.py и выведем список изменений, внесённых в репозиторий.
Выводом команды git diff --cached является содержимое файла fib.py, каждая строка которого помечена знаком «+», поскольку файл fib.py ранее отсутствовал в репозитории. Сделаем новый коммит:
~$ mkdir repo
~$ cd repo
~/repo$ echo "def fib(n):
> fibs = [0, 1]
> for _ in range(n):
> fibs.append(fibs[-1] + fibs[-2])
> return fibs[-2]" > fib.py
~/repo$ git init
Initialized empty Git repository in /home/artyom/Github/repo/.git/
~/repo$ git add fib.py
~/repo$ git diff --cached
diff --git a/fib.py b/fib.py
new file mode 100644
index 0000000..719362a
--- /dev/null
+++ b/fib.py
@@ -0,0 +1,5 @@
+def fib(n):
+ fibs = [0, 1]
+ for _ in range(n):
+ fibs.append(fibs[-1] + fibs[-2])
+ return fibs[-2]
~/repo$ git commit -m "Initial commit"
[master (root-commit) bb07669] Initial commit
1 file changed, 5 insertions(+)
create mode 100644 fib.py
Реализованный в записанной в файл fib.py функции fib алгоритм вычисления \(n\)-го числа Фибоначчи сейчас имеет пространственную сложность \(O(n)\), поскольку для вычисления \(n\)-го числа необходимо создать список fibs, содержащий n + 2 вычисленных чисел.
Улучшим функцию fib, заменив список fibs на 2 переменные, в которых находятся 2 числа Фибоначчи, вычисленных последними – пространственная сложность исправленного алгоритма составит \(O(1)\).
Обновим файл fib.py, добавим его в область индексирования и выведем список внесённых в файл изменений при помощи команды git diff --cached:
~/repo$ echo "def fib(n):
> a, b = 0, 1
> for _ in range(n):
> a, b = b, a + b
> return a" > fib.py
~/repo$ git add .
~/repo$ git diff --cached
diff --git a/fib.py b/fib.py
index 719362a..34ac5a2 100644
--- a/fib.py
+++ b/fib.py
@@ -1,5 +1,5 @@
def fib(n):
- fibs = [0, 1]
+ a, b = 0, 1
for _ in range(n):
- fibs.append(fibs[-1] + fibs[-2])
- return fibs[-2]
+ a, b = b, a + b
+ return a
Каждая строка выведенного в консоль содержимого файла fib.py помечена знаком «+», помечена знаком «-» или не помечена вовсе. Команда git diff расставляет метки на основе выявленной разницы между старым содержимым изменённого файла и его новым содержимым – добавленная в изменённый файл строка помечается знаком «+», удалённая строка помечается знаком «-», а строки, оставленные без изменений, не помечаются.
Исходя из вывода утилиты git diff можно сделать вывод, что для преобразования функции fib в её улучшенный вариант потребовалось удалить 3 строки с кодом, обрабатывающим список вычисленных чисел Фибоначчи fibs, и добавить 3 строки с кодом для работы с переменными a и b, содержащими 2 числа, вычисленных последними.
3.2.2. Расстояние Левенштейна
Теперь попробуем реализовать утилиту, аналогичную git diff, на основе модифицированного редакционного расстояния, предложенного в 1965 г. советским и российским математиком В.И. Левенштейном [37].
В работе [37] исследовались вопросы передачи двоичной информации с исправлением ошибок, однако расстояние Левенштейна сегодня применяется и для сравнения последовательностей из символов, отличных от нулей и единиц.
Расстояние Левенштейна может быть определено как минимальное число операций замены, вставки и удаления символов, необходимых для преобразования одной последовательности символов в другую.
Расстояние Левенштейна можно определить как:
| $$ f(\text{a}, \text{b}, i, j) = \begin{cases} \max(i, j), & \text{если } i = 0 \text{ или } j = 0, \\ f(\text{a}, \text{b}, i-1, j-1), & \text{если } \text{a}_i = \text{b}_j, \\ 1 + \min \left( \begin{array}{} f(\text{a}, \text{b}, i, j-1), \\ f(\text{a}, \text{b}, i-1, j), \\ f(\text{a}, \text{b}, i-1, j-1) \end{array} \right), & \text{если } \text{a}_i \neq \text{b}_j. \end{cases} $$ | (4) |
В формуле (4) \(\text{a}\) и \(\text{b}\) – это сравниваемые последовательности символов, \(i\) – это номер символа в последовательности \(\text{a}\), \(j\) – номер символа в последовательности \(\text{b}\). Номера 1-х символов в последовательностях \(\text{a}\) и \(\text{b}\) равны 1, начальным значением \(i\) является длина \(\text{a}\), начальным значением \(j\) является длина \(\text{b}\).
Если номер символа \(i\) в формуле (4) равен 0, то это значит, что в \(\text{a}\) больше не осталось символов, и чтобы превратить пустую последовательность в \(\text{b}\), необходимо выполнить \(j\) операций вставки символа в \(\text{a}\). Если номер символа \(j\) в формуле (4) равен 0, то необходимо выполнить \(i\) операций удаления символа из \(\text{a}\), поскольку в \(\text{b}\) больше не осталось символов. Если символ \(\text{a}_i\), имеющий номер \(i\) в последовательности \(\text{a}\), равен символу \(\text{b}_j\), то необходимо уменьшить номера символов \(i\) и \(j\) без увеличения значения расстояния Левенштейна.
Если символы \(\text{a}_i\) и \(\text{b}_j\) не равны друг другу, то редакционное расстояние по формуле (4) всегда увеличивается на 1, после чего необходимо или вставить в \(\text{a}\) символ из \(\text{b}\), или удалить из \(\text{a}\) символ, присутствующий в \(\text{b}\), или заменить символ \(\text{a}_i\) на символ \(\text{b}_j\) – выбирается действие, которое приводит к наименьшему редакционному расстоянию.
Попробуем реализовать утилиту командной строки для вычисления расстояния Левенштейна на языке Python по формуле (4).
Поместим в файл diff.py следующий код:
import sys
from functools import cache
@cache
def diff(a, b, i=0, j=0):
if i == len(a):
return len(b) - j
if j == len(b):
return len(a) - i
if a[i] == b[j]:
return diff(a, b, i + 1, j + 1)
return 1 + min(
diff(a, b, i, j + 1),
diff(a, b, i + 1, j),
diff(a, b, i + 1, j + 1))
print(diff(sys.argv[1], sys.argv[2]))
Для удобства при сравнении последовательностей будем двигаться не от последних символов в \(\text{a}\) и \(\text{b}\) к первым, как в формуле (4), а от первых символов к последним. Для вычисления длин последовательностей воспользуемся стандартной функцией len.
Для ускорения вычислений значений рекурсивной функции diff мы воспользовались механизмом запоминания промежуточных результатов, применив к реализованной функции декоратор cache из модуля functools [12].
Проверим работу программы, попробовав вычислить из командной строки редакционное расстояние:
~$ python diff.py столб слон
3
~$ python diff.py стол слон
2
~$ python diff.py слон слон
0
Легко убедиться в корректности работы функции diff, вручную вычислив расстояние Левенштейна между строками, использованными в качестве примеров, по формуле (4). Например, для преобразования строки «столб» в строку «слон» необходимо выполнить 3 действия – из первой строки удалить последний символ «б», заменить 2-й символ «т» на «л», заменить 4-й символ «л» на «н». Расстояние Левенштейна между строками «столб» и «слон» равно 3.
3.2.3. diff на основе расстояния Левенштейна
Модифицируем реализованный алгоритм вычисления расстояния Левенштейна следующим образом: операцию замены одного символа на другой преобразуем в последовательность операций удаления старого символа и добавления нового путём исключения в формуле (4) из аргументов функции min 3-го выражения, соответствующего замене символа.
Кроме того, теперь функция diff будет работать не с последовательностями символов, а с последовательностями строк. Результатом её работы станет не численное значение редакционного расстояния, а список пар, содержащих метку строки и саму строку – тем самым мы добавим в нашу утилиту командной строки diff.py поддержку вывода меток для отличающихся строк, как в выводе команды git diff.
Для операции добавления строки меткой является символ «+», для операции удаления – символ «-», а операция замены в модифицированном расстоянии Левенштейна не поддерживается:
import sys
from functools import cache
@cache
def diff(a, b, i=0, j=0):
if i == len(a):
return [('+', b[x]) for x in range(j, len(b))]
if j == len(b):
return [('-', a[x]) for x in range(i, len(a))]
if a[i] == b[j]:
return [(' ', a[i])] + diff(a, b, i + 1, j + 1)
return min(
[('+', b[j])] + diff(a, b, i, j + 1),
[('-', a[i])] + diff(a, b, i + 1, j),
key=len)
with open(sys.argv[1]) as file:
a = tuple(file.readlines())
with open(sys.argv[2]) as file:
b = tuple(file.readlines())
for op, line in diff(a, b):
print(op, line.rstrip())
В обновлённой функции diff, как и в git diff, метки указываются только для добавленных строк и для удалённых строк, а строки, оставшиеся без изменений, никак не помечаются. Списки кортежей, состоящих из метки строки и самой строки, генерируются при помощи списковых включений [12] и склеиваются при помощи оператора сложения списков.
При помощи функции open мы открываем на чтение 2 файла, пути к которым передаются как аргументы командной строки. Кортежи, состоящие из строк, содержащихся в файлах с указанными именами, подаются на вход функции diff. Результат работы diff выводится построчно в stdout.
Сравним результат работы обновлённой утилиты diff.py с результатом работы команды git diff. Для этого создадим файл fib.py, содержащий реализацию алгоритма вычисления \(n\)-го числа Фибоначчи с пространственной сложностью \(O(n)\), а также файл fib_new.py, содержащий реализацию улучшенного алгоритма с пространственной сложностью \(O(1)\). После этого выведем на экран различия между 2 файлами с кодом на Python при помощи утилиты diff.py и команды git diff:
~$ echo "def fib(n):
> fibs = [0, 1]
> for _ in range(n):
> fibs.append(fibs[-1] + fibs[-2])
> return fibs[-2]
>" > fib.py
~$ echo "def fib(n):
> a, b = 0, 1
> for _ in range(n):
> a, b = b, a + b
> return a
>" > fib_new.py
~$ git diff --no-index fib.py fib_new.py
diff --git a/fib.py b/fib_new.py
index 719362a..34ac5a2 100644
--- a/fib.py
+++ b/fib_new.py
@@ -1,5 +1,5 @@
def fib(n):
- fibs = [0, 1]
+ a, b = 0, 1
for _ in range(n):
- fibs.append(fibs[-1] + fibs[-2])
- return fibs[-2]
+ a, b = b, a + b
+ return a
~$ python diff.py fib.py fib_new.py
def fib(n):
+ a, b = 0, 1
- fibs = [0, 1]
for _ in range(n):
+ a, b = b, a + b
+ return a
- fibs.append(fibs[-1] + fibs[-2])
- return fibs[-2]
Опция --no-index команды git diff позволяет найти различия между файлами, находящимися вне git-репозитория.
Вывод нашей утилиты diff.py, основанной на модифицированном расстоянии Левенштейна, в котором, в отличие от [37], нет операции замены, похож на вывод команды git diff. Однако, сначала выводятся добавленные строки с меткой «+», и только после них – удалённые строки с меткой «-». Кроме того, отсутствует заголовок, содержащий имена сравниваемых файлов и номера строк.
3.2.4. Упражнения
Задача 1. Оцените diff-алгоритмы, такие как Patience, Minimal, Histogram, Myers [36], с точки зрения различия получаемых результатов на конкретных примерах. Какой алгоритм Вы считаете предпочтительным и почему?
Задача 2. Детально сравните работу реализованной утилиты diff.py и команды git diff с diff-алгоритмом, используемым в git diff по умолчанию. Объясните различия в выводе. Исправьте реализацию diff.py, чтобы добиться идентичного поведения.
Задача 3. С использованием функции расстояния Левенштейна можно получить последовательность команд редактирования, которые превращают исходную последовательность в результат. Это может помочь компактно хранить данные – для измененной версии файла мы храним только команды, которые производят эти изменения.
Реализуйте генератор кода, который из исходной последовательности создаёт последовательность-результат с помощью минимального числа операций вставки, замены и удаления. Пример работы такого генератора, реализованного на Python:
~$ python diff-gen.py "достаток" "остаточный"
x[7] = y[9]
x.insert(7, y[8])
x.insert(7, y[7])
x.insert(7, y[6])
del x[0]
Задача 4. Реализуйте графический интерфейс для утилиты diff.py. В графическом интерфейсе должна поддерживаться подсветка как удалённых и добавленных строк, так и отличающихся символов в старой и новой строке. Постарайтесь сделать графический интерфейс похожим графический интерфейс приложения GitHub Desktop, показанный на рис. 27.

Задача 5. Добавьте поддержку вывода результатов работы утилиты diff.py в формате HTML. Постарайтесь сделать результат похожим на графический интерфейс, показанный на рис. 27.
3.3. Модель git
3.3. Модель git
3.3.1. Наивное управление версиями
В этом разделе рассмотрим процесс создания модели СКВ git с поддержкой создания коммитов, связанных с разными версиями файлов и папок, хранящихся в контентно-адресуемой файловой системе [36], а также вывода истории коммитов в виде графа.
Начнём с рассмотрения наивного подхода к управлению версиями проекта с исходным кодом, основанного на сохранении разных версий файлов в разных папках, без использования СКВ. Создадим в командной оболочке Linux несколько версий простого проекта, содержащего файл с исходным кодом, файл с лицензией и файл с документацией:
~$ mkdir v1
~$ echo "MIT" > v1/license
~$ tree --noreport v1
v1
└── license
~$ cp -r v1 v2
~$ echo "app" > v2/readme.md
~$ tree --noreport v2
v2
├── license
└── readme.md
~$ cp -r v1 v3
~$ mkdir v3/src
~$ echo "print('hello')" > v3/src/hello.py
~$ tree --noreport v3
v3
├── license
└── src
└── hello.py
~$ cp -r v3 v4
~$ cp -r v2/readme.md v4
~$ tree --noreport v4
v4
├── license
├── readme.md
└── src
└── hello.py
Первой версией нашего проекта станет папка v1 с файлом license, содержащим внутри строку MIT, записанную в файл при помощи перенаправления вывода. Вторая версия — папка v2, основанная на v1, но с новым файлом readme.md. Третья версия, в свою очередь, — это папка v3, созданная на основе v1, но с новой папкой src внутри, содержащей файл hello.py с программой на языке Python. Четвёртая версия — папка v4, содержащая результат объединения версий v2 и v3. Команда tree с параметром --noreport печатает в stdout дерево файлов и папок без дополнительных сведений о количестве файлов в папке.
Создание новых версий проекта на основе уже существующих выполняется копированием папки с проектом при помощи команды cp, а слияние версий выполняется вручную. Очевидно, что использование такого подхода трудозатратно и неэффективно — для проекта с множеством версий придётся создать множество папок, а информация, хранящаяся в них, будет повторяться.
3.3.2. Управление версиями в git
Распределённая СКВ git позволяет отслеживать изменения файлов репозитория и в любой момент переключаться между его версиями. С git легко вести работу над одним проектом одновременно и независимо сразу нескольким программистам, с последующим объединением разных версий репозитория в одну при помощи команды git merge. Такая функциональность обеспечивается за счёт сохранения всех версий файлов репозитория на компьютере каждого программиста в специальном формате — в контентно-адресуемой файловой системе (Content-Addressable Storage, CAS) [36].
Использование git позволит обойтись без создания 4 папок:
~$ mkdir repo
~$ cd repo
~/repo$ git init
Initialized empty Git repository in ~/repo/.git/
~/repo$ echo "MIT" > license
~/repo$ git add .
~/repo$ git commit -qm "Init"
~/repo$ tree --noreport
.
└── license
~/repo$ git checkout -b docs
Switched to a new branch 'docs'
~/repo$ echo "app" > readme.md
~/repo$ git add .
~/repo$ git commit -qm "Docs"
~/repo$ tree --noreport
.
├── license
└── readme.md
~/repo$ git checkout master
Switched to branch 'master'
~/repo$ mkdir src
~/repo$ echo "print('hello')" > src/hello.py
~/repo$ git add .
~/repo$ git commit -qm "Code"
~/repo$ tree --noreport
.
├── license
└── src
└── hello.py
~/repo$ git merge docs -qm "Merge"
~/repo$ tree --noreport
.
├── license
├── readme.md
└── src
└── hello.py
При помощи git init мы создали новый репозиторий в папке repo. Затем добавили в него файл license, добавили файл в область индексирования командой git add . и сделали первый коммит Init, связанный с текущим набором файлов в репозитории. Команда git add . добавляет в область индексирования всё содержимое текущей директории. Опция -m команды git commit позволяет задать текст сообщения к коммиту, а опция -q отключает вывод подробных сведений об операции в stdout.
После коммита Init мы создали новую ветку docs при помощи команды git checkout с опцией -b — опция -b указывает, что необходимо создать новую ветку с заданным именем, а не переключиться на существующую. После добавления файла readme.md мы сделали первый коммит в ветке docs и переключились на ветку master, используемую по умолчанию. Затем мы создали новый файл hello.py в новой папке src и сделали коммит Code в ветке master, после чего выполнили слияние веток master и docs при помощи git merge, создав ещё один коммит.
Граф коммитов нашего git-репозитория легко визуализировать, воспользовавшись командой git log с опцией --graph:
~/repo$ git log --graph --oneline
* 12c5bb6 (HEAD -> master) Merge
|\
| * 7ce8f07 (docs) Docs
* | 1071c39 Code
|/
* f0e0c14 Init
В выведенном графе вершины обозначены символом *, справа от каждой вершины указаны первые 7 символов хэш-значений коммитов и сообщения к коммитам, а в круглых скобках справа от последнего коммита в ветке указано имя ветки. Метка HEAD указывается напротив активного в настоящий момент коммита. Опция --oneline команды git log позволяет вывести историю коммитов в краткой форме.
3.3.3. Модель git на Python
Теперь перейдём к созданию модели git на языке Python. Начнём с реализации контентно-адресуемой файловой системы [36] — представим её в виде словаря objects, ключом в котором является хэш-значение, вычисляемое для сохраняемого объекта. Сохраняемый объект, в свою очередь, представляет из себя пару, состоящую из заголовка и данных. Заголовок содержит тип объекта. Формат данных объекта зависит от типа объекта.
Создадим файл git.py и поместим в него следующий код:
from pprint import pprint
objects = {}
def make_object(header, content):
data = (header, content)
h = hash(data)
objects[h] = data
return h
def make_blob(data):
return make_object('blob', data)
make_blob('app')
make_blob("print('hello')")
pprint(objects)
Функция make_object создаёт объект data и сохраняет его в словаре objects. Объект — это пара, состоящая из заголовка header и содержимого content. Затем вычисляется хэш-значение для полученной пары (header, content) при помощи стандартной функции hash, возвращающей целое. Хэш-значение используется в качестве ключа объекта в словаре objects.
Функция make_blob специализирует функцию make_object для сохранения в словаре objects содержимого файла. Функция pprint из стандартного модуля pprint позволяет вывести в stdout структуру данных с автоматически расставленными отступами.
Проверим работу git.py:
~$ python git.py
{-5552424307104227732: ('blob', "print('hello')"),
-2447526263321356918: ('blob', 'app')}
Теперь реализуем рекурсивную функцию make_tree, которая сохраняет всё содержимое заданной папки в словарь objects. Добавим следующий код в файл git.py, заменив при этом вызов make_blob на вызов make_tree в конце файла git.py:
import os
def make_tree(path):
table = []
for name in os.listdir(path):
p = os.path.join(path, name)
if os.path.isfile(p):
with open(p) as f:
table.append((name, make_blob(f.read())))
elif os.path.isdir(p):
table.append((name, make_tree(p)))
return make_object('tree', tuple(table))
make_tree('v4')
pprint(objects)
Функция make_tree читает содержимое папки, доступной по пути path, при помощи функции listdir из стандартного модуля os [12]. Содержимое папки сохраняется в словарь objects как таблица table, причём в первой колонке таблицы указывается имя файла или папки name, а во второй колонке — хэш-значение объекта, связанного с именем из первой колонки таблицы, полученное или от функции make_tree, или от функции make_blob. Вызов функции make_tree с аргументом v4 сохраняет в словарь objects содержимое папки с именем v4.
Проверим работу обновлённой модели git:
~$ tree --noreport v4
v4
├── readme.md
└── src
└── hello.py
~$ python git.py
{1565835151721922343: ('blob', "print('hello')"),
5218520276485572056: ('blob', 'app'),
6679246622821842587: ('blob', 'MIT'),
8983795902379471365: ('tree', (
('readme.md', 5218520276485572056),
('license', 6679246622821842587),
('src', 9119572560804270185))),
9119572560804270185: ('tree', (
('hello.py', 1565835151721922343),))}
Словарь objects содержит граф, показанный на рис. 28.

Добавим поддержку коммитов в модель git. Сведения о коммитах также сохраним в словаре objects, при этом с каждым коммитом будет связано имя автора коммита, сообщение к коммиту, а также папка папка, содержащая одну из версий репозитория. Теперь объекты, хранящиеся в нашей контентно-адресуемой файловой системе, могут быть трёх типов: commit, tree и blob.
Попробуем создать несколько коммитов, с каждым из которых связано содержимое одной из ранее созданных папок v1, v2, v3 и v4.
Обновим файл git.py и добавим в него следующий код:
def make_commit(tree, parents, author, message):
return make_object('commit', (tree, parents, author, message))
c1 = make_commit(make_tree('v1'), (), 'Peter', 'Init')
c2 = make_commit(make_tree('v2'), (c1,), 'Arty', 'Docs')
c3 = make_commit(make_tree('v3'), (c1,), 'Peter', 'Code')
c4 = make_commit(make_tree('v4'), (c2, c3), 'Peter', 'Merge')
pprint(objects)
Функция make_commit специализирует функцию make_object для создания объекта с типом commit в словаре objects. Вызов функции make_commit приводит к созданию нового коммита, связанного с папкой, уже сохранённой в словаре objects в результате вызова функции make_tree.
Словарь objects теперь содержит граф, показанный на рис. 29.

Круглые вершины на рис. 29 соответствуют коммитам, а прямоугольные — объектам типа tree или blob. У каждого коммита может быть один или несколько связанных с ним родительских коммитов. Коммит, с которым связано несколько родительских коммитов — это результат слияния коммитов.
Поскольку ключами в словаре objects являются хэш-значения, вычисленные для содержимого файлов или папок, в objects не может существовать несколько объектов типа blob или tree с одинаковым содержимым. Вследствие этого в вершины графа, соответствующие объектам типа blob, может входить несколько стрелок. Как показано на рис. 29, объекты типа tree могут переиспользоваться схожим образом, однако для каждого коммита создаётся свой объект tree с обновлённым списком файлов и папок, поскольку коммит изменяет содержимое репозитория.
3.3.4. Упражнения
Задача 1. Создайте визуализатор содержимого словаря objects с использованием инструмента Graphviz [14], позволяющий получить изображение графа коммитов, показанного на рис. 29.
Задача 2. Реализуйте на основе разработанной модели git инструмент командной строки, поддерживающий создание коммитов с указанием автора коммита и сообщения к коммиту, а также переключение на нужную версию репозитория по хэш-значению коммита.
Задача 3. Реализуйте в модели git операции для создания веток и переключения между ними.
Задача 4. Реализуйте в модели git операции merge и rebase.
Задача 5. Сделайте из модели git настоящую СКВ: для хранения репозитория и объектов используйте БД sqlite.
3.4. Разбор объектов git-репозитория
3.4. Разбор объектов git-репозитория
3.4.1. Служебная папка .git
В этом разделе рассмотрим команду git cat-file [36] и её применение для получения сведений об объектах, хранящихся в контентно-адресуемой файловой системе git-репозитория.
Для хранения объектов типа commit, tree и blob в реализованной модели git использовался словарь objects, однако в «настоящем» git каждый объект хранится в отдельном файле. Попробуем проанализировать содержимое служебной папки .git созданного в предыдущем разделе репозитория repo. Начнём с визуализации текущего содержимого репозитория в виде дерева при помощи команды tree, а затем переместимся в папку .git и выведем список служебных файлов и папок git:
~$ cd repo
~/repo$ tree --noreport
.
├── license
├── readme.md
└── src
└── hello.py
~$ cd .git
~/repo/.git$ ls
branches COMMIT_EDITMSG config description HEAD hooks index info logs objects ORIG_HEAD refs
Для получения сведений об объектах типа commit, tree и blob репозитория repo необходимо выяснить, с каким коммитом связано текущее содержимое репозитория. Для этого при помощи команды cat выведем на экран содержимое файла HEAD – указателя на активную в настоящий момент ветку или на коммит [8].
Сейчас HEAD указывает на файл refs/heads/master. В этом файле указано хэш-значение объекта типа commit, содержащего сведения о последнем коммите в ветке master:
~/repo/.git$ cat HEAD
ref: refs/heads/master
~/repo/.git$ cat refs/heads/master
12c5bb662c4d2f814ab614b6a393d0dc647d9632
Для хэширования объектов в git используется алгоритм SHA-1 (Secure Hash Algorithm 1), результатом работы которого является последовательность из 20 байт. Однако, выведенная на экран строка, содержащая хэш-значение коммита, состоит из 40 символов. Это обусловлено тем, что результатом преобразования одного байта в строку, содержащую число в шестнадцатеричной системе счисления, является последовательность из двух символов. Например, байт со значением 255 в десятичной системе будет представлен как FF в шестнадцатеричной системе.
Используя выведенное в stdout хэш-значение коммита, легко найти файл со сведениями об объекте типа commit в папке objects. Для этого необходимо разделить выведенную строку на 2 части – первая часть соответствует первому байту хэш-значения и содержит 2 шестнадцатеричных символа, а вторая часть соответствует оставшимся байтам и содержит 38 шестнадцатеричных символов.
Первая часть выведенного хэш-значения – это имя папки, а вторая часть – это имя файла в папке, содержащего данные объекта:
~/repo/.git$ ls objects/12
c5bb662c4d2f814ab614b6a393d0dc647d9632
~/repo/.git$ du -b objects/12/c5bb662c4d2f814ab614b6a393d0dc647d9632
184 objects/12/c5bb662c4d2f814ab614b6a393d0dc647d9632
Команда du с опцией -b позволяет оценить размер файла с указанным именем в байтах. Из вывода команд ls и du следует, что папка с именем 12, находящаяся внутри папки objects, содержит единственный файл с именем c5bb662c4d2f814ab614b6a393d0dc647d9632, состоящий из 184 байт. Этот файл – сжатый, и прочитать его содержимое при помощи утилиты cat не получится.
3.4.2. Утилита cat-file
Утилита cat-file позволяет получать сведения об объектах git по их хэш-значению. Попробуем при помощи команды git cat-file получить сведения о последнем коммите в ветке master, на которую указывает HEAD:
~/repo$ git cat-file -t 12c5bb662c4d2f814ab614b6a393d0dc647d9632
commit
~/repo$ git cat-file -p 12c5bb662c4d2f814ab614b6a393d0dc647d9632
tree 30271f5c2174f651b2258352a5ae65208bd61891
parent 1071c39bac0d67990aacd2c5916fd0d3068333d1
parent 7ce8f078ea430a24690786931bd7ab7aa646d845
author User <user@example.com> 1738851204 +0300
committer User <user@example.com> 1738851204 +0300
Merge
Выполнение команды git cat-file с опцией -t позволяет получить тип объекта, связанного с указанным хэш-значением. Выполнение той же команды с опцией -p позволяет вывести в stdout данные объекта. Как и в реализованной нами ранее модели git, объект типа commit содержит хэш-значения родительских коммитов в строках с префиксом parent, хэш-значение связанного с коммитом объекта папки в строке с префиксом tree, а также сведения об авторе коммита в строке с префиксом author и текст сообщения к коммиту в последующих строках.
Попробуем вывести содержимое связанного с коммитом объекта типа tree, а также содержимое объекта типа blob для одного из находящихся внутри папки файлов:
~/repo$ git cat-file -t 30271f5c2174f651b2258352a5ae65208bd61891
tree
~/repo$ git cat-file -p 30271f5c2174f651b2258352a5ae65208bd61891
100644 blob a22a2da24d1ceeef3d0c2f1f4f68923f55b8d4cc license
100644 blob b80f0bd60822d4fa4893de455958ef32f6c521bf readme.md
040000 tree 11a1faff831b47b7268b7981726a177b36358639 src
~/repo$ git cat-file -t a22a2da24d1ceeef3d0c2f1f4f68923f55b8d4cc
blob
~/repo$ git cat-file -p a22a2da24d1ceeef3d0c2f1f4f68923f55b8d4cc
MIT
Объекты с содержимым файлов имеют тип blob, а объекты-папки имеют тип tree. Для объекта типа tree команда git cat-file построчно выводит в stdout список содержащихся внутри файлов и папок. Каждая строка в выводе содержит права доступа к файлу или папке [8], тип объекта (blob для файла и tree для папки), хэш-значение связанного с именем объекта, а также имя объекта. Для объекта типа blob команда git cat-file выводит в stdout его содержимое.
3.4.3. Реализация cat-file на Python
Теперь попробуем реализовать на языке Python утилиту командной строки, позволяющую выводить в stdout сведения об объектах из служебной папки .git по заданному хэш-значению. Начнём с реализации утилиты, имитирующей поведение команды git cat-file с опцией -t.
Создадим новый файл cat-file.py и поместим в него следующий код, содержащий 2 функции – cat_file и cat_object:
import os, sys, zlib
def cat_object(obj):
header, content = obj.split(b'\0', 1)
header, size = header.split(b' ')
print(header.decode())
def cat_file(repo, h):
path = os.path.join(repo, '.git', 'objects', h[:2], h[2:])
with open(path, 'rb') as f:
cat_object(zlib.decompress(f.read()))
cat_file(sys.argv[1], sys.argv[2])
Функция cat_file принимает на вход путь к папке git-репозитория и хэш-значение объекта, тип которого необходимо вывести в stdout, и вычисляет путь к файлу с данными объекта path. В качестве имени папки используются первые 2 символа хэш-значения, а в качестве имени файла – остальные 38 символов. Файл по пути path открывается на чтение в двоичном режиме. Прочитанные байты подаются на вход функции decompress из стандартного модуля zlib, функция decompress выполняющей разжатие содержимого файла со сведениями об объекте git.
Затем сведения об объекте git подаются на вход функции cat_object, которая отделяет заголовок от данных, используя байт со значением 0 в качестве разделителя. Заголовок имеет формат <тип> <размер>, где <тип> может принимать значение commit, tree или blob, а <размер> – это число байт, которое занимают данные объекта content. Следовательно, для вывода в stdout типа объекта необходимо разделить заголовок по символу пробела.
Префикс b, указанный перед строками в функции cat_object, необходим, поскольку на вход функции cat_object поступают данные объекта в виде массива байт. Преобразование массива байт в строку выполняется перед выводом заголовка объекта header в консоль при помощи вызова метода decode.
Сравним вывод cat-file.py с выводом команды git cat-file с опцией -t:
~$ python cat-file.py repo 12c5bb662c4d2f814ab614b6a393d0dc647d9632
commit
~$ python cat-file.py repo 30271f5c2174f651b2258352a5ae65208bd61891
tree
~$ cd repo
~/repo$ git cat-file -t 12c5bb662c4d2f814ab614b6a393d0dc647d9632
commit
~/repo$ git cat-file -t 30271f5c2174f651b2258352a5ae65208bd61891
tree
Доработаем утилиту cat-file.py таким образом, чтобы можно было получать сведения об объекте git по его хэш-значению в формате, похожем на формат вывода команды git cat-file с опцией -p.
Обновим содержимое файла cat-file.py:
import os, sys, zlib
def cat_tree(content):
while content:
mode, content = content.split(b' ', 1)
name, content = content.split(b'\0', 1)
h, content = content[:20], content[20:]
print(f'{int(mode):06}', h.hex(), name.decode())
def cat_object(obj):
header, content = obj.split(b'\0', 1)
header, size = header.split(b' ')
match header.decode():
case 'commit' | 'blob':
print(content.decode().rstrip())
case 'tree':
cat_tree(content)
def cat_file(repo, h):
path = os.path.join(repo, '.git', 'objects', h[:2], h[2:])
with open(path, 'rb') as f:
cat_object(zlib.decompress(f.read()))
cat_file(sys.argv[1], sys.argv[2])
Мы добавили в файл cat-file.py новую функцию cat_tree, а также обновили содержимое функции cat_object. Теперь, если объект имеет тип commit или blob, то байты с данными объекта преобразуются в строку и выводятся в stdout. В случае, если объект имеет тип tree, управление передаётся в функцию cat_tree, которая осуществляет разбор байт content с данными об объектах, содержащихся в папке.
Функция cat_tree сначала разделяет набор байт по первому встреченному символу пробела. Прочитанное значение слева от пробела mode – это права доступа к файлу или папке. После этого оставшаяся часть набора байт разделяется по первому встреченному байту со значением 0. Прочитанное значение name слева от нулевого байта – это имя файла или папки. Следующие за нулевым байтом 20 символов содержат хэш-значение h объекта файла или папки с именем name.
Проверим работу обновлённой утилиты cat-file.py:
~$ python cat-file.py repo 12c5bb662c4d2f814ab614b6a393d0dc647d9632
tree 30271f5c2174f651b2258352a5ae65208bd61891
parent 1071c39bac0d67990aacd2c5916fd0d3068333d1
parent 7ce8f078ea430a24690786931bd7ab7aa646d845
author User <user@example.com> 1738851204 +0300
committer User <user@example.com> 1738851204 +0300
Merge
~$ python cat-file.py repo 30271f5c2174f651b2258352a5ae65208bd61891
100644 a22a2da24d1ceeef3d0c2f1f4f68923f55b8d4cc license
100644 b80f0bd60822d4fa4893de455958ef32f6c521bf readme.md
040000 11a1faff831b47b7268b7981726a177b36358639 src
~$ python cat-file.py repo a22a2da24d1ceeef3d0c2f1f4f68923f55b8d4cc
MIT
Реализованная в файле cat-file.py функция cat_file, позволяющая по хэш-значению объекта получить его данные, может использоваться и при построении графа объектов, сохранённых в служебной папке .git.
Граф объектов, построенный для анализируемого в данном разделе репозитория repo, показан на рис. 30.

Круглые вершины на рис. 30 соответствуют коммитам, а прямоугольные — объектам типа tree или blob, как и в графе коммитов, построенном для модели git и показанном на рис. 29. Кроме того, в граф на рис. 30 также включены первые 7 шестнадцатеричных символов хэш-значений каждого объекта.
Подграф показанного на рис. 30 графа коммитов легко построить при помощи стандартных средств, воспользовавшись командой git log с опциями --graph и --oneline:
~$ cd repo
~/repo$ git log --graph --oneline
* 12c5bb6 (HEAD -> master) Merge
|\
| * 7ce8f07 (docs) Docs
* | 1071c39 Code
|/
* f0e0c14 Init
3.4.4. Упражнения
Задача 1. Вывод реализованной утилиты cat-file.py почти совпадает с выводом команды git cat-file с опцией -p, однако в выводе содержимого объекта типа tree отсутствуют сведения о типах содержащихся в папке объектов – blob или tree. Исправьте утилиту cat-file так, чтобы её вывод совпадал с выводом git cat-file:
~$ python cat-file.py repo 30271f5c2174f651b2258352a5ae65208bd61891
100644 a22a2da24d1ceeef3d0c2f1f4f68923f55b8d4cc license
100644 b80f0bd60822d4fa4893de455958ef32f6c521bf readme.md
040000 11a1faff831b47b7268b7981726a177b36358639 src
~$ cd repo
~/repo$ git cat-file -p 30271f5c2174f651b2258352a5ae65208bd61891
100644 blob a22a2da24d1ceeef3d0c2f1f4f68923f55b8d4cc license
100644 blob b80f0bd60822d4fa4893de455958ef32f6c521bf readme.md
040000 tree 11a1faff831b47b7268b7981726a177b36358639 src
Задача 2. Создайте визуализатор содержимого .git/objects с использованием инструмента Graphviz [14], позволяющий получить изображение графа коммитов, показанного на рис. 29. Воспользуйтесь реализованной ранее функцией cat_file. Эту функцию потребуется доработать так, чтобы она возвращала сведения об объектах вместо вывода их содержимого в stdout.
Задача 3. Создайте инструмент undo.py для восстановления файла по имени, если файл более не присутствует в текущем дереве.
Задача 4. Создайте инструмент для извлечения всех сообщений коммитов из заданного репозитория.
Задача 5. Разберитесь, что собой представляют упакованные (packed) объекты репозитория. Доработайте свой вариант cat-file.py для поддержки упакованных объектов.
4.1. Инфраструктура как код
4.1. Инфраструктура как код
Параметры конфигурации ПО обычно хранятся в специальном виде, доступном для редактирования пользователями и другими программами. Для хранения может использоваться специальная база данных, но наиболее распространенным вариантом хранения настроек программы являются конфигурационные файлы, содержимое которых написано на одном из конфигурационных языков. Многие программные инструменты конфигурирования ПО используют конфигурационные языки.
Конфигурационный язык – язык описания параметров конфигурации ПО. Конфигурационный файл представлен на конфигурационном языке и предназначен для редактирования пользователями и другими программами.
К преимуществам конфигурационных языков относят:
- удобный человеко-читаемый синтаксис, который дает возможность внести изменения в конфигурацию быстрее, чем при использовании GUI-инструментов;
- удобный машинно-читаемый синтаксис для автоматической обработки параметров конфигурационного файла внешними программами;
- ограниченные средства программируемости, позволяющие автоматизировать рутинные действия.
В качестве конфигурационных языков могут использоваться:
- непрограммируемые форматы описания конфигурации,
- языки программирования общего назначения,
- программируемые предметно-ориентированные языки для задач конфигурационного управления.
Современный подход «инфраструктура как код» (infrastructure as code) предполагает широкое использование в конфигурационном управлении конфигурационных языков.
4.2. Формальные языки и грамматики
4.2. Формальные языки и грамматики
Компьютерные языки являются подмножеством формальных языков.
Формальный язык состоит из множества строк конечной длины, называемых словами. Слова состоят из символов, а символы содержатся в алфавите – конечном множестве символов.
В этом определении предполагается, что для установления принадлежности некоторой строки формальному языку необходимо сначала перечислить все возможные строки на этом языке, что, разумеется, является непрактичным подходом.
Рассмотрим иной способ определения языка. Регулярный язык, являющийся теоретической основой регулярных выражений, может быть описан следующим образом:
- Пустая строка ε или одиночный символ из алфавита являются регулярным языком.
- Если \(A\) это регулярный язык, то \(A^{*}\) также является регулярным языком. Операция \(A^{*}\) обозначает повторение \(R\) 0 или более раз.
- Если \(A\) и \(B\) – регулярные языки, то \(A | B\) тоже является регулярным языком. Операция \(A | B\) обозначает выбор из \(A\) или \(B\).
- Если \(A\) и \(B\) – регулярные языки, то \(A B\) тоже является регулярным языком. Операция \(A B\) обозначает последовательность: \(A\), за которым следует \(B\).
Введенных базовых операций достаточно, чтобы определить дополнительные конструкции, использующиеся в регулярных выражениях. Например, конструкцию A+ можно определить, как AA*, а конструкция A? заменяется конструкцией A|ε.
Мощности регулярных языков, тем не менее, не хватает для описания многих важных компьютерных языков. В частности, с помощью регулярного языка невозможно описать конструкции произвольной вложенности. Это, в том числе, касается разбора и HTML-кода, и даже простого выражения, в котором присутствуют лишь правильно расставленные скобки с произвольной глубиной вложенности.
Другой способ определения формального языка – формальная грамматика, задающая общие правила построения языка. Этот способ используется для определения синтаксиса компьютерных языков. Формальная грамматика – метаязык, то есть язык, который определяет язык. В частности, для описания регулярных языков может быть задана регулярная грамматика.
Формальные грамматики на практике используются для следующих целей:
- лексический и синтаксический разбор компьютерного языка;
- порождение случайных фраз на компьютерном языке, например, для задач тестирования.
Более мощным, чем регулярные языки, формализмом описания компьютерных языков является контекстно-свободная грамматика.
Контекстно-свободную грамматику можно представить себе в виде программы на ограниченном языке программирования. В этом языке есть «имена функций» (нетерминалы, имена правил) и «определения функций» (тела правил). В определениях содержатся «вызовы функций» и «вывод символов» определяемого языка (терминалов). Работа программы начинается с «главной функции», называемой начальным нетерминалом.
Благодаря возможности использования рекурсии в грамматических правилах контекстно-свободные грамматики широко используются для определения синтаксиса компьютерных языков.
Контекстно-свободную грамматику можно представить в форме так называемой железнодорожной или синтаксической диаграммы.
На рис. 31 показан пример грамматики арифметического выражения.

В текстовой форме контекстно-свободная грамматика определяется с помощью формы Бэкуса-Наура (БНФ). На практике, в БНФ часто добавляются конструкции регулярных выражений для упрощения описания синтаксиса.
Ниже представлен пример грамматики арифметического выражения в БНФ:
<Значение> ::= <Число> | <Переменная>
<Операция> ::= "+" | "-" | "*" | "/"
<Выражение> ::= <Значение> | <Выражение> <Операция> <Выражение> | "(" <Выражение> ")"
Для автоматизации задач лексического (уровень базовых лексических единиц) и синтаксического (уровень иерархических конструкций) разбора существуют специальные инструменты. Примерами таких инструментов являются ANTLR [42] для Java, SLY [43] для Python и Flex/Bison для C++.
4.3. Компьютерные языки
4.3. Компьютерные языки
Рассмотрим представленную на рис. 32 упрощенную классификацию компьютерных языков.

Тьюринг-полными называются языки, на которых можно реализовать модель машины Тьюринга, а значит – реализовать любой алгоритм. К таким языкам относится, в частности, большинство языков программирования.
Тьюринг-полнота необязательно является полезным свойством языка. Для Тьюринг-неполных, ограниченных языков может быть легче осуществить статический анализ и преобразования на уровне компилятора.
Предметно-ориентированные языки (domain-specific language, DSL) ориентированы задачи некоторого узкого класса, поэтому, зачастую являются Тьюринг-неполными. Основное достоинство DSL – использование предметно-ориентированной нотации.
Известно множество специализированных нотаций. Например, нотация химических формул или нотная нотация. Математики древних цивилизаций описывали математические задачи на естественном языке с использованием сложных систем счисления. Поэтому установление даже некоторых тривиальных для современного школьника, оперирующего алгебраической нотацией, математических фактов могло было затруднено для математика древности. Заслуживает внимания гипотеза лингвистической относительности, которая предполагает наличие влияния структуры языка на мышление.
4.3.1. Простые форматы описания конфигурации
Одним из старейших форматов описания как кода, так и данных являются S-выражения языка Lisp. Это нотация для древовидных структур, реализованных в виде вложенных списков.
Грамматика S-выражений в БНФ:
<s-exp> ::= <atom> | '(' <s-exp-list> ')'
<s-exp-list> ::= <sexp> <s-exp-list> |
<atom> ::= <symbol> | <integer> | #t | #f
Пример S-выражения:
(users
((uid 1) (name root) (gid 1))
((uid 108) (name peter) (gid 108))
((uid 109) (name alex) (gid 109)))
К недостаткам S-выражений для описания конфигурации относятся:
- сложность чтения для человека синтаксиса с большим числом скобок;
- нет стандарта S-выражений для описания конфигурационных данных.
Классическим способом представления файлов конфигурации является формат INI из Windows, а также схожие с ним варианты conf из Unix. В основе формата – последовательность пара ключ-значение. Пары схожего назначения объединяются в секции:
[секция_1]
параметр1=значение1
параметр2=значение2
[секция_2]
параметр1=значение1
параметр2=значение2
В (расширенной) БНФ:
ini ::= {section}
section ::= "[" name "]" "\n" {entry}
entry ::= key "=" value "\n"
Здесь фигурные скобки обозначают повторение 0 или более раз.
Пример INI-файла (system.ini):
; for 16-bit app support
[386Enh]
woafont=dosapp.fon
EGA80WOA.FON=EGA80WOA.FON
EGA40WOA.FON=EGA40WOA.FON
CGA80WOA.FON=CGA80WOA.FON
CGA40WOA.FON=CGA40WOA.FON
[drivers]
wave=mmdrv.dll
timer=timer.drv
[mci]
[network]
Bios=1438818414
SSID=29519693
К недостаткам INI для описания конфигурации относятся:
- отсутствие поддержки вложенных конструкций;
- отсутствие стандарта INI для описания конфигурационных данных.
Еще недавно наибольшую популярность среди форматов конфигурационных данных имел XML (eXtensible Markup Language).
XML разрабатывался как язык с простым формальным синтаксисом, удобный для создания и обработки документов программами и одновременно удобный для чтения и создания документов человеком, с подчеркиванием нацеленности на использование в Интернете.
В самом базовом виде XML напоминает S-выражения, в которых вместо скобок используются открывающийся и закрывающийся именованные теги.
Пример XML-данных:
<?xml version="1.0" encoding="UTF-8"?>
<shiporder orderid="889923"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="shiporder.xsd">
<orderperson>John Smith</orderperson>
<shipto>
<name>Ola Nordmann</name>
<address>Langgt 23</address>
<city>4000 Stavanger</city>
<country>Norway</country>
</shipto>
<item>
<title>Hide your heart</title>
<quantity>1</quantity>
<price>9.90</price>
</item>
</shiporder>
Важной особенностью XML является поддержка специальных схем для определения корректности XML-данных: DTD (Document Type Definition), XML Schema и другие. DTD определяет:
- состав элементов, которые могут использоваться в XML документе;
- описание моделей содержания, т.е. правил вхождения одних элементов в другие;
- состав атрибутов, с какими элементами XML документа они могут использоваться;
- каким образом атрибуты могут применяться в элементах;
- описание сущностей, включаемых в XML документ.
В XML Schema дополнительно введены типы данных для элементов. Фрагмент XML Schema описания элемента item из примера выше:
<xs:element name="item" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="title" type="xs:string"/>
<xs:element name="note" type="xs:string" minOccurs="0"/>
<xs:element name="quantity" type="xs:positiveInteger"/>
<xs:element name="price" type="xs:decimal"/>
</xs:sequence>
</xs:complexType>
</xs:element>
К недостаткам XML для описания конфигурации относится высокая сложность формата, как для чтения человеком, так и для программного разбора.
Формат JSON (JavaScript Object Notation) основан на синтаксисе JavaScript. Изначально он использовался в качестве текстового формата обмена данными, но со временем все чаще стал применяться и в качестве формата описания конфигурации приложения.
В JSON используются следующие типы данных:
- число в формате double;
- строка;
- логическое значение true или false;
- массив значений любого поддерживаемого типа;
- объект – словарь пар ключ-значение, где ключ – строка, а значение – любой поддерживаемый тип;
- специальное значение null.
Пример JSON-данных:
{"menu": {
"id": "file",
"value": "File",
"popup": {
"menuitem": [
{"value": "New", "onclick": "CreateNewDoc()"},
{"value": "Open", "onclick": "OpenDoc()"},
{"value": "Close", "onclick": "CloseDoc()"}
]
}
}}
Для проверки корректности JSON-данных в формат позже была добавлена схема – JSON Schema, которая во многом схожа с XML Schema.
К недостаткам JSON для описания конфигурации относится отсутствие поддержки комментариев.
Формат YAML (YAML Ain’t Markup Language) предназначен для сериализации данных, но также часто используется в качестве конфигурационного языка. YAML с точки зрения синтаксиса имеет сходство с языком Python – для определения вложенности конструкций используются отступы. Особенностью YAML является возможность создания (с помощью &) и использования (с помощью *) ссылок на элементы документа. Это позволяет не приводить полностью повторно встречающиеся данные.
Пример YAML-файла:
–
receipt: Oz-Ware Purchase Invoice
date: 2012-08-06
customer:
first_name: Dorothy
family_name: Gale
items:
- part_no: A4786
descrip: Water Bucket (Filled)
price: 1.47
quantity: 4
- part_no: E1628
descrip: High Heeled "Ruby" Slippers
size: 8
price: 133.7
quantity: 1
bill-to: &id001
street: |
123 Tornado Alley
Suite 16
city: East Centerville
state: KS
ship-to: *id001
...
К недостаткам YAML для описания конфигурации относятся:
- сложность редактирования сильно вложенных элементов, проблемы с отступом;
- сложность стандарта YAML (размер файла спецификации больше, чем у XML).
Формат TOML (Tom’s Obvious, Minimal Language) специально предназначен для использования в конфигурационных файлах. Его синтаксис основан на INI. Спецификация TOML не имеет БНФ-описания.
Пример TOML-данных:
# This is a TOML document
title = "TOML Example"
[owner]
name = "Tom Preston-Werner"
dob = 1979-05-27T07:32:00-08:00
[database]
enabled = true
ports = [ 8001, 8001, 8002 ]
data = [ ["delta", "phi"], [3.14] ]
temp_targets = { cpu = 79.5, case = 72.0 }
[servers]
[servers.alpha]
ip = "10.0.0.1"
role = "frontend"
[servers.beta]
ip = "10.0.0.2"
role = "backend"
К недостаткам TOML для описания конфигурации относится сложность спецификации языка.
4.3.2. Языки общего назначения как конфигурационные
Использование языка программирования общего назначения для описания конфигурации ПО обладает рядом преимуществ по сравнению с простыми непрограммируемыми конфигурационными форматами:
- поддержка функций;
- поддержка циклов;
- поддержка типов данных;
- поддержка импорта файлов.
Благодаря поддержке функций, циклов и разбиению файлов на модули достигается принцип DRY (Don’t repeat yourself) – не допускать повторения одной и той же информации в программе. В результате конфигурационные файлы имеют компактную, удобную для редактирования форму.
Поддержка типов данных, в том числе пользовательских, позволяет осуществить на уровне типов проверку корректности программы – то, для чего в таких форматах, как XML, используются схемы.
Некоторые примеры использования языков общего назначения в качестве конфигурационных языков:
- В текстовом редакторе Emacs используется встроенный язык Elisp для описания конфигурации;
- В БД Tarantool используется Lua;
- Конфигурации на языке Python используются в setuptools и Jupyter;
- В Gradle конфигурация сборки может быть описана на Groovy и Kotlin.
К недостаткам языков общего назначения для задач конфигурирования относятся:
- небезопасное исполнение стороннего кода;
- сложность, чрезмерная выразительность языка (Тьюринг-полнота), мешающая задачам анализа и порождения конфигурационных данных.
4.3.3. Программируемые конфигурационные языки
К основным DRY-элементам программируемых конфигурационных языков, можно отнести:
- переменные;
- арифметические операции;
- функции в математическом смысле;
- ветвления;
- операции построения многоэлементных массивов и иных составных объектов;
- операции импорта сторонних модулей;
Jsonnet является расширенным вариантом JSON и представляет собой Тьюринг-полный конфигурационный язык с динамической типизацией.
Пример описания данных на Jsonnet:
local makeUser(user) = {
local home = std.format("/home/%s", user),
local privateKey = std.format("%s/.ssh/id_ed25519", home),
local publicKey = std.format("%s.pub", privateKey),
home: home,
privateKey: privateKey,
publicKey: publicKey
};
[
makeUser("bill"),
makeUser("jane")
]
Результат преобразования в JSON:
[
{
"home": "/home/bill",
"privateKey": "/home/bill/.ssh/id_ed25519",
"publicKey": "/home/bill/.ssh/id_ed25519.pub"
},
{
"home": "/home/jane",
"privateKey": "/home/jane/.ssh/id_ed25519",
"publicKey": "/home/jane/.ssh/id_ed25519.pub"
}
]
Еще одним программируемым конфигурационным языком является Dhall. Этот язык со статической типизацией, основанный на принципах функционального программирования. Авторы определяют Dhall, как JSON + функции + типы + импорты. Важной особенностью Dhall является тот факт, что это Тьюринг-неполный язык. В Dhall имеется режим нормализации представления, при котором все языковые абстракции разворачиваются и результат представляет собой уровень представления JSON или YAML.
Пример описания данных на Dhall:
let makeUser = \(user : Text) ->
let home = "/home/${user}"
let privateKey = "${home}/.ssh/id_ed25519"
let publicKey = "${privateKey}.pub"
in { home = home
, privateKey = privateKey
, publicKey = publicKey
}
in [ makeUser "bill"
, makeUser "jane"
]
5.1. Планирование задач
5.1. Планирование задач
Сборка программного проекта может состоять из большого числа этапов, среди которых: компиляция модулей, подготовка файлов данных и преобразование их форматов, генерирование документации. Чтобы не повторять рутинные действия из раза в раз можно написать программу на языке интерпретатора командной строки. Тем не менее, работа простых сборочных скриптов на больших проектах часто занимает непозволительно большое время.
К системе сборки [44] могут быть предъявлены следующие требования:
- каждая сборочная задача выполняется не более одного раза, а сами задачи выполняются лишь в том случае, если они прямо или косвенно зависят от входных данных, которые изменились с предыдущей сборки проекта;
- задачи, которые прямо и косвенно не зависят друг от друга, имеется возможность выполнить параллельно.
К основным элементам системы сборки относятся:
- таблица, в которой содержатся ключи – задачи и значения – файлы или другие данные, определяющие результат выполнения задачи;
- план выполнения задач с определением действий по выполнению каждой задачи и указанием стартовой задачи;
- алгоритм планировщика задач и способ определения задач, которые не нуждаются в перестроении.
Система сборки принимает на вход таблицу и план выполнения задач и возвращает таблицу в актуальном состоянии – для стартовой задачи и всех ее зависимостей выполнены необходимые действия.
Система сборки принимает описание задачи, целевой ключ и хранилище и возвращает измененное хранилище, в котором целевой ключ и всего его зависимости принимают актуальные значения.
Таблица может быть представлена одним из следующих основных способов:
- файловая система вместо отдельной таблицы и время модификации файлов. Если время модификации одного из файлов-зависимостей задачи более новое, чем время модификации файла-результата самой задачи – необходимо перестроить задачу;
- хранилище с хеш-значениями файлов в качестве ключей. Если хеш файла, связанного с задачей, изменился, то задачу необходимо перестроить.
План выполнения задач описывается на языке системы сборки. Такие языки можно отнести к классу конфигурационных языков.
Системы сборки различаются по типу используемого алгоритма планировщика:
- алгоритм топологической сортировки графа зависимостей задач;
- алгоритм на основе рестартов задач;
- алгоритм на основе приостановки задач;
Алгоритм на основе рестартов задач устроен следующим образом. Рассмотрим ситуацию, когда выполняется задача \(A\) и было установлено, что она имеет зависимую задачу \(B\), которая должна быть выполнена в первую очередь. В этом случае выполнение задачи \(A\) отменяется, выполняется задача \(B\), затем выполнение задачи \(A\) стартует повторно.
Алгоритм на основе приостановки задач отличается тем, что не отменяет выполнение задачи \(A\) полностью, а лишь приостанавливает это выполнение. После завершения задачи \(B\) система сборки возвращается к приостановленной ранее задаче \(A\) и продолжает ее выполнение.
Также системы сборки различаются по типу зависимостей:
- статические зависимости;
- динамические зависимости.
Статические зависимости устанавливаются на этапе составления плана выполнения задач. Динамические зависимости обнаруживаются в процессе сборки. Например, одна из задач формирует файл-список файлов-рисунков, для каждого из которых необходимо выполнить отдельную задачу – преобразовать рисунок в некоторый графический формат.
В системе сборки может применяться техника раннего среза (early cutoff) – если задача выполнена, но ее результат не изменился с предыдущей сборки, то нет необходимости исполнять зависимые задачи, то есть процесс сборки можно завершить ранее. На практике такая ситуация определяется по хеш-значению файла, связанного с задачей. Например, если в файл main.c был добавлен новый комментарий, сборка может быть остановлена после определения отсутствия изменений в хеш-значении объектного файла – main.o.
При использовании облачной системы сборки скорость сборки может быть существенно увеличена, благодаря разделению результатов сборки между отдельными разработчиками. Облачная система сборки может поддержать вариант сборки, при котором локально образуются только конечные результаты сборки, а все промежуточные файлы остаются в облаке.
На рис. 33 приведен пример сценария работы с облачной системой сборки. Пользователь совершает следующие действия:
- Загружает исходные тексты, их хеш-значения 1, 2 и 3.
- Затем пользователь запрашивает сборку main.exe. Система сборки определяет с помощью изучения истории предыдущих сборок, что кто-то уже скомпилировал ранее эти исходные тексты для main.exe. Результаты их сборки хранятся в облаке с хешами 4 (util.o) и 5 (main.o). Система сборки далее определяет, что для зависимостей с такими хешами есть готовый main.exe с хешем 6. По ключу 6 из облачного хранилища извлекается конечный результат;
- Далее пользователь изменяет util.c, и его хеш становится равен 7. В облаке комбинации хешей (7, 2) не существует, то есть ранее никто еще не компилировал такой вариант исходного кода. Процесс продолжается до получения нового main.exe, после чего новые варианты файлов и их хеш-значения сохраняются в облаке.

5.1.1. Топологическая сортировка
Топологическая сортировка является популярным алгоритмом планировщика в системах сборки.
Рассмотрим пример, показанный на рис. 34. Здесь целевой задачей является «экипировка», для достижения которой необходимо выполнить подзадачи в корректном порядке. Таким порядком может быть следующий:
1 3 2 5 7 4 6 8
Легко заметить, что это не единственный корректный порядок. Следующий вариант тоже имеет право на существование:
1 3 4 2 6 5 7 8
Обратите внимание, что такие задачи, как, например, 4 и 5, можно было бы выполнить одновременно, поскольку они не зависят друг от друга. Одевающемуся человеку это выполнить проблематично, но в случае сборки ПО возможность параллельного выполнения подзадач является полезной.
Простой алгоритм топологической сортировки состоит из следующих шагов:
- Найти узлы графа без входных зависимостей и добавить их к списку результатов.
- Удалить ранее найденные узлы. Если узлов в графе не осталось, то возвратить результат. В противном случае перейти к п.1.
На практике чаще используется алгоритм топологической сортировки, основанный на обходе графа в глубину.
Топологическая сортировка определена для графов, не имеющих циклических зависимостей между задачами. На практике циклы в графе могут возникнуть при использовании динамических зависимостей.

5.2. Система сборки Make
5.2. Система сборки Make
Система сборки Make является старейшей в своем классе (1976 г.) и при этом до сих пор активно используется разработчиками.
К основным характеристикам Make относятся:
- Использование файловой системы, вместо таблицы, а также времени модификации файлов для определения необходимости пересборки задач;
- Поддержка только статических зависимостей;
- Использование алгоритма топологической сортировки в качестве алгоритма планировщика.
В Make используется специальный конфигурационный файл с именем Makefile для определения плана сборки. Основными элементами декларативного языка Makefile являются определения переменных, а также правила сборки, состоящие из задачи-цели и ряда задач-зависимостей для этой цели.
Рассмотрим пример определения Makefile для графа «экипировки» на рис. 34.
equipment: shoes jacket
@echo $@
underwear:
@echo $@
socks: underwear
@echo $@
shirt: underwear
@echo $@
trousers: shirt
@echo $@
sweater: shirt
@echo $@
shoes: trousers
@echo $@
jacket: sweater
@echo $@
В этом примере имеется последовательность правил следующего вида:
цель: зависимости
действие
Действия представляют собой последовательность строк, это команды для интерпретатора командной строки ОС. Командами могут быть, в частности, вызовы компилятора или вызовы инструментов преобразования форматов данных.
Обратите внимание, что строки действий выделяются символом табуляции. Именно табуляцией, а не пробелами. Если была получена ошибка missing separator при выполнении Makefile, то речь идет именно о путанице с пробелами и табуляциями.
Цели и зависимости представляют собой, с точки зрения make, имена файлов. У этих файлов и проверяется время последней модификации. Если файл цели задачи отсутствует, то сборка этой задачи всегда будет произведена.
Вызов make в каталоге, содержащем приведенный выше Makefile, выдаст следующую информацию:
underwear
shirt
trousers
shoes
sweater
jacket
equipment
В правилах могут использоваться специальные переменные, среди которых:
$@. Имя цели.$<. Имя первой зависимости.$^. Список имен всех зависимостей.
Переменные в Makefile определяются, как показано в примере ниже:
SHOW = @echo $@
%:
$(SHOW)
equipment: shoes jacket
underwear:
socks: underwear
shirt: underwear
trousers: shirt
sweater: shirt
shoes: trousers
jacket: sweater
Здесь используется определение шаблона с помощью %, что обозначает произвольное имя. В рассматриваемом примере это приводит к выполнению указанного действия для всех целей.
Утилита make по умолчанию начинает выполнение с первой цели, указанной в Makefile. Можно также указать и конкретную цель для сборки:
# make trousers
underwear
shirt
trousers
В Makefile часто добавляются псевдоцели, такие как all (собрать все) и clean (очистить от временных файлов). Для того, чтобы утилита make могла отличить псевдоцели от файлов, используется специальная цель .PHONY.
6.1. Что такое виртуализация
6.1. Что такое виртуализация
Определение слова «виртуальный» можно найти, к примеру, в толковом словаре Ожегова:
«ВИРТУАЛЬНЫЙ, -ая, -ое; -лен, -льна (спец.). Несуществующий, невозможный. Виртуальные миры. Виртуальная реальность (несуществующая,воображаемая). В. образ (в компьютерных играх)».
Некоторые сюжетные элементы на тему виртуальности из мира фантастики вполне встречаются и в компьютерном мире. Возьмем ситуацию, когда герой обнаруживает внутри виртуального мира еще один, внутренний виртуальный мир. Это похоже на запуск в браузере ОС Linux, в которой, в свою очередь, запускается программа DOSBox, имитирующая работу старого компьютера под управлением MS-DOS.
Можно вспомнить еще одну типичную для фантастических произведений ситуацию, когда герой пытается понять, в реальном ли он находится мире, или же – в виртуальном. Подобная проблема возникает, к примеру, для выполняемой компьютерной программы, которая пытается определить, не происходит ли нежелательный анализ ее поведения под управлением виртуальной машины.
В случае компьютерной системы «реальным миром» является хост-система, а «виртуальным миром» – виртуальная машина, гостевая система или, в более общем смысле, некоторый виртуальный ресурс.
Виртуализацией будем называть создание виртуальной (абстрактной, имитируемой) версии ресурса компьютерной системы. Для виртуализации типичными являются следующие свойства:
- изолированность виртуального ресурса от хост-системы и от других виртуальных ресурсов,
- разделение ресурсов хост-системы между виртуальными ресурсами.
На рис. 35 показаны основные виды виртуализации.

Понятие виртуальной машины связано с самим понятием алгоритма, определяющего процесс вычислений, который может быть выполнен на машине Тьюринга или на каком-то ином абстрактном вычислителе, полном по Тьюрингу. Доказательство полноты по Тьюрингу достигается демонстрацией реализации внутри интересующего нас вычислителя виртуальной машины, имитирующей работу какого-либо из вычислителей, Тьюринг-полнота которого известна.
На рис. 36 представлены основные техники обеспечения виртуализации.

6.2. Языковые виртуальные машины
6.2. Языковые виртуальные машины
Языковые виртуальные машины предназначены для исполнения программ на конкретном языке программирования (или семействе таких языков) в условиях различных программно-аппаратных платформах без перекомпиляции. Иными словами, упрощается портирование программ.
Рассмотрим классический пример П-кода (P-code) для виртуального выполнения программ на языка Паскаль, предложенный в середине 70-х годов. Специальный вариант компилятора Паскаля порождает платформонезависимый П-код. Для различных программно-аппаратных платформ реализованы интерпретаторы П-кода, также включающие библиотеку времени выполнения. В результате компилятор существует только в одном варианте и для каждой из новых целевых платформ достаточно реализовать небольшую программу – интерпретатор П-кода.
К ярким историческим примерам успешного портирования компьютерных игр на множество различных игровых платформ относятся текстовая игра Zork (1978), реализованная в коде виртуальной Z-машины в 1979 году, а также игра Another World (1991), имеющая изощренную виртуальную машину с поддержкой многопоточности, графики и звука.
К популярным современным языковым виртуальным машинам можно отнести:
- Java Virtual Machine (JVM). Виртуальная машина для Java.
- Common Language Runtime (CLR). Виртуальная машина среды .NET.
- CPython Virtual Machine. Виртуальная машина языка Python.
- WebAssembly (WASM). Виртуальная машина для веб-приложений.
Языковая виртуальная машина выполняет команды абстрактного процессора, ориентированного на конструкции конкретного языка или целого семейства языков. Программу в таком представлении принято называть байткодом. Такое название закрепилось исторически, оно связано с виртуальной машиной языка Smalltalk, в которой большинство команд кодировалось одним байтом.
Поскольку реальные процессоры, в большинстве случаев, не поддерживают на аппаратном уровне исполнение байткода, то используется программная модель языковой машины.
Архитектуры виртуальных машин, как и архитектуры реальных процессоров, можно разделить на два класса:
- стековые машины,
- регистровые машины.
Рассмотрим байткод различных виртуальных машин для вычисления выражения
$$b b - 4 a c.$$
В стековой модели вычислений это выражение представляется в постфиксной форме записи:
b b * 4 a * c * -
В регистровой модели вычислений то же выражение может быть представлено трехадресным кодом:
t1 = b * b
t2 = 4 * a
t3 = t2 * c
t4 = t1 - t3
В JVM используется стековая модель вычислений:
0: iload_1
1: iload_1
2: imul
3: iconst_4
4: iload_0
5: imul
6: iload_2
7: imul
8: isub
9: ireturn
В CPython тоже используется стековая модель вычислений:
0 LOAD_FAST 1 (b)
2 LOAD_FAST 1 (b)
4 BINARY_MULTIPLY
6 LOAD_CONST 1 (4)
8 LOAD_FAST 0 (a)
10 BINARY_MULTIPLY
12 LOAD_FAST 2 (c)
14 BINARY_MULTIPLY
16 BINARY_SUBTRACT
18 RETURN_VALUE
Виртуальная машина языка Lua использует регистровую вычислительную модель (см. числа после имен операций):
1 MUL 3 1 1
2 MMBIN 1 1 8 ; __mul
3 MULK 4 0 0 ; 4
4 MMBINK 0 0 8 1 ; __mul 4 flip
5 MUL 4 4 2
6 MMBIN 4 2 8 ; __mul
7 SUB 3 3 4
8 MMBIN 3 4 7 ; __sub
9 RETURN1 3
10 RETURN0
Во многих случаях для выполнения байткода быстродействия интерпретатора оказывается недостаточно и может использоваться трансляция. Различают следующие варианты трансляции:
- AOT (Ahead-of-Time). Полная трансляция байткода в машинный код целевой платформы перед ее запуском.
- JIT (Just-in-Time). Динамическая трансляция областей программы прямо во время интерпретации байткода.
6.3. Виртуализация вычислительной системы
6.3. Виртуализация вычислительной системы
Устаревание программного и аппаратного обеспечения является серьезной проблемой в области информационных технологий. Здесь помощь может оказать виртуализация. Устаревшее оборудование, к которому уже не найти современных драйверов, может быть заменено своей виртуальной программной версией. Программа, предназначенная для выполнения на редкой или устаревшей вычислительной системе, может быть выполнена в рамках виртуальной машины уже на современном компьютере. Виртуализация также полезна для экономного управления вычислительными ресурсами. С использованием виртуализации пользователь на одном физическом компьютере может работать с несколькими виртуальными компьютерами, имеющим различные характеристики и использующими различные ОС. Этот подход используется для организации виртуальных серверов для веб-хостинга, а также применяется в сфере облачных вычислений.
Виртуализация уровня вычислительной системы [45] имеет давнюю историю. Еще в конце 60-х годов компания IBM реализовала в своей ОС CP/CMS поддержку виртуализации на аппаратном уровне. Таким образом было организована работа с несколькими программными версиями компьютера System/360-370. С массовым развитием персональных компьютеров интерес к виртуализации сильно угас. Возобновление этого интереса произошло уже в 1999 году, когда компания VMware выпустила коммерчески успешное ПО VMware Workstation для виртуализации работы ОС Linux и Windows на компьютерах с архитектурой x86.
Для организации виртуальной машины требуется специальный программный модуль – монитор виртуальных машин или гипервизор. Гипервизор управляет доступом виртуальных машин к физическим ресурсам хост-машины. В этом отношении гипервизор ведет себя аналогично ядру операционной системы. Гипервизоры разделяют на следующие два типа:
- Работает прямо на оборудовании хост-машины, без участия ОС.
- Работает в рамках хост-ОС и, возможно, использует модуль ядра для управления физическими ресурсами хост-машины.
Теоретические основы виртуализуемости, определяющие, насколько эффективно работает гипервизор, были предложены в 1974 году Ж. Попеком (G. Popek) и Р. Голдбергом (R. Goldberg). Рассмотрим подробнее суть предложений этих авторов.
Выделены следующие типы команд компьютера:
- Привилегированные. Выполнение которых вызывает исключение, если это выполнение происходит вне режима ядра ОС.
- Чувствительные. Команды, которые позволяют управлять состоянием компьютера или отслеживать это состояние.
- Безвредные. Остальные команды.
Сформулированы следующие свойства, которыми должен обладать гипервизор:
- Безвредные команды выполняются аппаратурой напрямую, без привлечения гипервизора.
- Программы влияют на доступные им ресурсы системы только опосредованно, с помощью гипервизора.
- Программа под управлением гипервизора выполняется точно так же, как и без оного, за исключением временных характеристик и объема доступных ресурсов.
Наконец, авторы сформулировали следующую теорему виртуализуемости: построение гипервизора, удовлетворяющего этим свойствам для заданного компьютера возможно, если множество чувствительных команд этого компьютера является подмножеством привилегированных команд.
Аппаратная виртуализация, основанная на обработке гипервизором исключений со стороны привилегированных команд, использовалась еще в старых ОС от компании IBM. Тем не менее, для персональных компьютеров архитектуры x86 долгое время представленная выше теорема не выполнялась. В начале 2000-х реализация гипервизора на архитектуре x86-64 требовала серьезных ухищрений. Использовалась, в частности, динамическая трансляция программы с целью замены чувствительных команд на соответствующие обращения к гипервизору. Кроме того, применялась техника паравиртуализации, при использовании которой в гостевую ОС должны быть внесены изменения, включающие обращения к гипервизору. Наконец, в середине 2000-х компании Intel и AMD добавили в свои процессоры аппаратную поддержку виртуализации. Современные процессоры поддерживают аппаратную виртуализацию как процессора, так и ОЗУ, а также устройств ввода-вывода.
При использовании виртуальной машины с отличающейся от хост-машины процессорной архитектурой необходима эмуляция, которая может быть реализована в виде интерпретатора машинного кода, а также на основе статического (AOT) или динамического (JIT) двоичного транслятора.
Одной из популярных программ для задач виртуализации вычислительных систем является QEMU. В этой программе реализована эмуляция ряда компьютеров различных архитектур с набором периферийных устройств. В QEMU поддерживается аппаратная виртуализация с использованием сторонних гипервизоров, в числе которых KVM (Kernel-based Virtual Machine) и HAXM (Hardware Accelerated Execution Manager).
Рассмотрим пример использования QEMU. Предположим, мы хотим использовать дистрибутив Linux Alpine на виртуальной машине с архитектурой x86-64. В первую очередь создадим виртуальный жесткий диск размером 1 Гбайт, на который будет установлен дистрибутив Linux:
qemu-img create -f qcow2 alpine.qcow2 1G
Созданный жесткий диск доступен в виде файла alpine.qcow2. Теперь необходимо запустить виртуальную систему x86-64 с объемом ОЗУ в 1 Гбайт для установки Alpine на виртуальный жесткий диск. При этом используется виртуальный CD-ROM и ISO-файл alpine-standard-3.14.2-x86_64.iso:
qemu-system-x86_64 -m 1G -cdrom alpine-standard-3.14.2-x86_64.iso -hda alpine.qcow2
После установки Alpine на жесткий диск можно перезагрузить виртуальную систему и далее работать с ней с помощью следующей команды:
qemu-system-x86_64 -m 1G -hda alpine.qcow2
6.3.1. Виртуализация приложения
Виртуализация приложения позволяет выполнять приложения на тех платформах, для которых они не были предназначены. При этом виртуализируются интерфейсы операционной системы. Примером виртуализации уровня приложения является система Wine, позволяющая запускать приложения для Windows внутри Linux.
В QEMU имеется эмуляция режима пользователя, которая позволяет выполнять Linux-приложения, скомпилированные для одной процессорной архитектуры, на другой процессорной архитектуре.
6.3.2. Виртуализация уровня ОС
При виртуализации уровня ОС виртуализация аппаратных ресурсов обычно отсутствует. Существует единственное хост-ядро ОС и набор изолированных друг от друга пользовательских пространств, подключаемых к нему. Такие подключаемые пользовательские пространства называются контейнерами. Каждый контейнер содержит отдельную копию файловой системы ОС с установленным набором программ. Использование контейнеров облегчает установку, использование и взаимодействие сложных программ. В отличие от виртуализации, контейнеризация не несет накладных расходов на выполнение гостевого ядра ОС.
Рассмотрим пример использования контейнеров в системе Docker. Установим контейнер дистрибутива Alpine:
docker pull alpine
Запустим (run) контейнер в интерактивном режиме (-it), вызвав командный интерпретатор sh в Alpine:
docker run -it alpine sh
Необходимо учитывать, что после окончания сеанса работы с контейнером все несохраненные данные исчезнут. Данные, которые необходимо сохранять, например, файлы базы данных, записываются в каталог хост-системы. Команда Docker -v указывает этот каталог, а также его представление в файловой системе контейнера (/my_data):
docker run -it -v "$(pwd)/my_data:/my_data" alpine sh
Для построения контейнера удобно использовать конфигурационный файл Dockerfile. Предположим, стоит задача построить контейнер на базе Alpine с добавленным интерпретатором языка Python. Для выполнения этой задачи `Dockerfile имеет следующий вид:
FROM alpine
RUN apk add python3
Команда FROM указывает в этом примере базовый контейнер, а команда RUN – те команды, которые необходимо выполнить в процессе построения контейнера.
7.1. Языки разметки
7.1. Языки разметки
Как известно, большинство программистов не любит писать документацию к своим проектам. На это есть причины. В частности, документацию трудно поддерживать в актуальном состоянии в процессе разработки программы. Кроме того, традиционный подход к ведению технической документации с использованием редакторов в духе Microsoft Word с точки зрения разработчика сильно отличается от процессов ведения программного проекта.
В связи с вышесказанным перспективным является подход «документация как код» (docs as code), основная идея которого в использовании для создания технической документации тех же процессов, что и для разработки программ. Подход «документация как код» отличается следующими особенностями:
- Использование текстовых языков разметки, удобных как для чтения человеком, так и с точки зрения машинной обработки;
- Использование текстовых языков описания графических материалов;
- Использование системы контроля версий для хранения проекта документации;
- Использование инструментов командной строки для автоматической проверки, сборки документации и непрерывной интеграции (continuous integration);
- Ориентация на выходной web-формат.
Языки разметки, помимо очевидной возможности написания текстов, поддерживают специальные команды, отвечающие за внешний вид и структурные особенности документа. В отличие от обычных WYSIWYG-редакторов («что вижу на экране, то и получу в документе»), язык разметки позволяет документ «запрограммировать», при этом «программа» на языке разметки и ее результат в виде документа отличаются друг от друга.
Очевидным примером языка разметки является HTML, но для задач составления документации было создано множество специальных языков, в частности:
- LaTeX;
- Markdown;
- reStructuredText;
- AsciiDoc.
Важным достоинством языка разметки является удобство использование системы контроля версий – в истории репозитория легко отследить изменения, внесенные в документ. Этого не удалось бы добиться с двоичными форматами в духе docx.
Одной из важнейших проблем проектирования языка разметки является обеспечение необходимой гибкости в компьютерной верстке документа при использовании облегченного, почти «невидимого» для пользователя командного языка.
7.1.1. TeX и LaTeX
Один из древнейших и, пожалуй, самый мощный язык разметки – TeX, который используется в одноименной системе компьютерной верстки. TeX был разработан Д. Кнутом в 1978 году для задач написания литературы в области компьютерных наук. В 1984 году Л. Лэмпорт создал набор макрорасширений для TeX под названием LaTeX. Сегодня LaTeX используется для написания статей в журналах по математике и физике, создания технических книг, дипломов и диссертаций.
LaTeX отличают средства автоматизации создания документов, это касается, в частности, построения списка литературы, нумерации элементов и ссылок на них, оптимизации размещения элементов на страницах и описания математических формул.
Ниже представлен пример простого документа в LaTeX:
\documentclass[14pt]{article} % Формат страниц
\usepackage{polyglossia} % Поддержка русского языка
\setmainlanguage{russian}
\setmainfont{Times New Roman} % Настройка шрифта
\title{Тестовый документ} % Заголовок
\author{П.Н. Советов} % Автор
\date{\today} % Дата создания
\begin{document} % Тело документа
\maketitle % Вставка заголовка
Это простой \textbf{пример} документа в \LaTeX.
\end{document}
Можно заметить, что команды в LaTeX предваряются символом \ и могут иметь аргументы, заключенные в скобки различных форм.
Результат компиляции документа с помощью xelatex показан на рис. 37.

Особый интерес представляет использующийся в LaTeX язык разметки математических формул. Формулы обрамляются символами $ (встраивание в текст) или $$ (в отдельной строке). Примеры простых формул представлены ниже:
$$
a^n + b^n = c^n
$$
$$
x_{1,2}=\frac{-b \pm \sqrt {b^2-4ac}}{2a}
$$
$$
f(x) = \frac{1}{\sigma \sqrt{2\pi} }
e^{-\frac{1}{2}\left(\frac{x-\mu}{\sigma}\right)^2}
$$
$$
\eta(T|a)= \sum_{v\in vals(a)} {\frac{|S_a{(v)}|}{|T|}
\cdot \eta\left(S_a{\left(v\right)}\right)}
$$
Результат компиляции формул представлен на рис. 38.

Знакомство с языком описания формул LaTeX очень полезно, поскольку этот язык или его подмножества используются во многих современных системах, например, в языке разметки Wikipedia.
7.1.2. Грамотное программирование
Как уже говорилось выше, особенную проблему представляет разделенность программного кода и документации на программный проект. Ранней попыткой решить указанную проблему является подход «грамотного программирования» (literate programming) Д. Кнута в виде системы WEB, созданной в 1984 году. WEB основана на системе TeX и позволяет вести документацию с внедренным в нее программным кодом.
С помощью инструмента weave из WEB-файла извлекается только часть, связанная с документацией. С помощью инструмента tangle из WEB-файла извлекается программный код. Схема работы WEB показана на рис. 39.

На рис. 40 показан пример LaTeX-документа, извлеченного из WEB-файла.

Из приведенного WEB-документа может быть извлечен также следующий код:
def insert(tree, key):
if not tree:
tree = Node(key)
elif key < tree.key:
tree = Node(tree.key, insert(tree.left, key), tree.right)
elif key > tree.key:
tree = Node(tree.key, tree.left, insert(tree.right, key))
return tree
В какой-то мере черты грамотного программирования унаследовала система Jupyter-блокнотов, в которой документы представлены в виде последовательности ячеек. Ячейка может либо содержать программный код, либо – документацию. Jupyter-блокноты используются, в основном, в области научно-технических расчетов и для анализа данных.
7.1.3. Markdown и Pandoc
Одним из простейших языков разметки является Markdown. Его авторы преследовали цель получения незаметного командного языка, чтобы файлы на Markdown было легко читать, как есть, даже без трансляции в какое-то выходное представление.
Ниже показаны примеры элементов синтаксиса Markdown:
# Заголовок 1
## Заголовок 2
## Заголовок 3
Параграф с текстом и [ссылкой](https://pandoc.org/).
Параграф с текстом, выделенным **жирным** и *курсивом*.
> Важная цитата (Автор)
Список элементов:
1. Первый.
1. Второй.
* Вложенный первый.
* Вложенный второй.
1. Третий.
| Поле 1 | Поле 2 |
| ----------- | ----------- |
| Данные 1 | Данные 3 |
| Данные 2 | Данные 4 |
```python
{
"name": "Ivan",
"last_name": "Drago",
"age": 25
}
```
Markdown, в силу простоты и читаемости своего синтаксиса, представляет собой возможную альтернативу LaTeX. Однако, при использовании более-менее сложного форматирования документов возможностей Markdown быстро перестанет хватать. В этой ситуации может помочь инструмент Pandoc [46], предназначенный для трансляции документов из одного представления в другое. Особенность Pandoc в том, что в нем поддерживается расширенный вариант Markdown, который, в свою очередь, можно дополнить рядом сторонних модулей.
Архитектура Pandoc показана на рис. 41. Работу Pandoc можно разбить на три этапа:
- Одно из входных представлений с помощью поддерживаемых трансляторов для чтения (readers) преобразуется во внутреннее представление Pandoc – дерево абстрактного синтаксиса.
- На уровне AST могут бы применены пользовательские фильтры (filters).
- Полученное AST с помощью поддерживаемых трансляторов для записи (writers) преобразуется в одно из выходных представлений.
В варианте markdown от Pandoс поддерживаются некоторые элементы LaTeX, в частности, язык описания математических формул.

7.2. Языки описания диаграмм
7.2. Языки описания диаграмм
Как и в случае текста, языки описания графических материалов позволяют легко вносить и отслеживать изменения в рисунок. Еще одним преимуществом таких языков является возможность автоматизации построения рисунков. Это касается, в частности, построения различных диаграмм на основе автоматического анализа классов и модулей из программного кода.
Одним из наиболее популярных инструментов в этой области является Graphviz, в котором для описания графов различного вида используется язык Dot.
Пример кода на языке Dot показан далее:
digraph G {
n1 [style=filled, color=brown1, label="1", shape=oval]
n2 [style=filled, color=darkolivegreen1, label="2", shape=box]
n3 [style=filled, color=aquamarine, label="3", shape=circle]
n1 -> n2 -> n3
n3 -> n1
}
Результат компиляции в графический файл представлен на рис. 42.

Еще одним популярным инструментом является PlantUML, предназначенный для создания как UML-диаграмм различного вида, так и для диаграмм иного вида (диаграммы Ганта, интеллект-карты и проч.).
Ниже представлен пример диаграммы, описанной на языке PlantUML:
@startuml
skinparam monochrome true
skinparam shadowing false
A -> B: шаг
activate B
B -> C: шаг
activate C
C --> C: действие
C -> B: шаг
deactivate C
B -> A: шаг
deactivate B
@enduml
Результат компиляции в графический файл представлен на рис. 43.

7.3. Генераторы документации
7.3. Генераторы документации
Очевидным способом объединения документации и программного кода является подробное комментирование программного кода. При внесении изменений в программу имеется возможность сразу же обновить документирующие поведение программы комментарии в коде. Существуют инструменты, позволяющие автоматически извлечь из файла программы специальным образом оформленные комментарии и оформить результат в виде справочной документации по программному модулю.
Примеры генераторов документации:
- Javadoc для языка Java;
- Doxygen для C++ и некоторых других языков;
- Расширения для системы Sphinx, поддерживающие целый ряд языков.
Ниже показан пример программы на языке C со специальными комментариями, поддерживаемыми системой Doxygen. Обратите внимание на специальные ключевые слова \file, \brief и \param:
/// \file main.cpp
/// Модуль main.
#include <stdio.h>
/// \brief Главная функция.
/// \param int argc Счетчик аргументов.
/// \param char **argv Указатель на аргументы.
int main(int argc, char **argv) {
return 0;
}
Далее приведен пример программы на языке Питон, с комментариями, поддерживаемыми системой Sphinx. Обратите внимание на специальные ключевые слова param, type и return:
"""
Модуль main.
"""
def main(x, y):
"""
Функция main.
:param x: Параметр x.
:type x: str
:param y: Параметр y.
:type y: int
:return: Ничего не возвращает.
"""
8.1. Работа с git из командной строки
8.1. Работа с git из командной строки
8.1.1. Разбор задачи
Рассмотрим пример работы с git из командной строки Linux. Пусть дан лог git-репозитория в виде графа:
* (dev) Merge branch 'master' into dev
|\
* | Add unit tests
| | M readme.md
| | A tests.py
| | * (HEAD -> master) Add features
| |/
| | M app.py
| | M compute.c
| | D readme.md
| * Accelerate computations
|/
| A compute.c
| M readme.md
* Initial commit
A app.py
A readme.md
Как показано в приведённом логе, git-репозиторий содержит ветку master, включающую в себя 3 коммита, и ветку dev, также включающую в себя 3 коммита. Последний коммит в ветке dev выполняет слияние веток, а первый коммит в ветке master также является первым коммитом в ветке dev.
Попробуем привести пустой git-репозиторий к состоянию, показанному выше. Создадим директорию в текущем каталоге и инициализируем в ней новый git-репозиторий:
~$ mkdir repo
~$ cd repo
~/repo$ git init
Initialized empty Git repository in /home/user/repo/.git/
Создадим в директории файлы README.md и app.py, добавим текущую директорию целиком в область индексирования командой git add . и выведем содержимое области индексирования в консоль при помощи команды git diff --cached:
~/repo$ echo "Sample app" > README.md
~/repo$ echo "print('Hello world')" > app.py
~/repo$ git add .
~/repo$ git diff --cached
diff --git a/app.py b/app.py
new file mode 100644
index 0000000..f7d1785
--- /dev/null
+++ b/app.py
@@ -0,0 +1 @@
+print('Hello world')
diff --git a/README.md b/README.md
new file mode 100644
index 0000000..827457e
--- /dev/null
+++ b/README.md
@@ -0,0 +1 @@
+Sample app
Из вывода команды git diff --cached следует, что системе контроля версий теперь известно о добавлении в репозиторий 2 новых файлов. Зафиксируем внесённые изменения:
~/repo$ git commit -m "Initial commit"
[master (root-commit) 902fffb] Initial commit
2 files changed, 2 insertions(+)
create mode 100644 app.py
create mode 100644 README.md
Создадим ещё один коммит в ветке master, добавив в репозиторий файл compute.c и изменив README.md:
~/repo$ echo "int main(void) { printf(\"hello, world\n\"); }" > compute.c
~/repo$ echo "Sample app with C code" > README.md
~/repo$ git add .
~/repo$ git diff --cached --stat
README.md | 2 +-
compute.c | 1 +
2 files changed, 2 insertions(+), 1 deletion(-)
~/repo$ git commit -m "Accelerate computations"
[master fa6960d] Accelerate computations
2 files changed, 2 insertions(+), 1 deletion(-)
create mode 100644 compute.c
Команда git diff с опцией --stat позволяет получить краткие сведения об изменившихся файлах из области индексирования, в которую файлы репозитория были ранее добавлены командой git add. Выведем историю коммитов в виде графа:
~/repo$ git log --graph --name-status --pretty=oneline
* fa6960d552a199adea9151189d267f62e69d96cc (HEAD -> master) Accelerate computations
| A compute.c
| M README.md
* 902fffb0f20c66f37366681722465e4e4edd7e2c Initial commit
A app.py
A README.md
Команда git log выдаёт информацию о коммитах в хронологическом порядке, а опция --graph позволяет визуализировать историю коммитов в виде графа, где коммиты обозначены символом *, за которым следует хэш коммита и сообщение к коммиту. С опцией --pretty=oneline сведения о коммитах выводятся в компактном виде, без подробных сведений об авторе. Опция --name-status позволяет обогатить вывод команды git log именами и статусами файлов, связанных с коммитом.
Статус файла может принимать одно из следующих значений: * M (modified) – файл изменён; * A (added) – файл добавлен в репозиторий; * D (deleted) – файл удалён из репозитория; * R (renamed) – файл переименован.
Граф выше содержит 2 связанных коммита. Добавим заключительный коммит в ветку master:
~/repo$ rm README.md
~/repo$ echo "int main() { printf("Hello, world\n"); }" > compute.c
~/repo$ echo "print('Hello, world')" > app.py
~/repo$ git add .
~/repo$ git diff --cached --stat
app.py | 2 +-
compute.c | 2 +-
README.md | 1 -
3 files changed, 2 insertions(+), 3 deletions(-)
~/repo$ git commit -m "Add features"
[master d2062c3] Add features
3 files changed, 2 insertions(+), 3 deletions(-)
delete mode 100644 README.md
~/repo$ git log --graph --name-status --pretty=oneline
* d2062c36a8bcf56edc46a6bc69b254b371c40b22 (HEAD -> master) Add features
| M app.py
| M compute.c
| D README.md
* fa6960d552a199adea9151189d267f62e69d96cc Accelerate computations
| A compute.c
| M README.md
* 902fffb0f20c66f37366681722465e4e4edd7e2c Initial commit
A app.py
A README.md
Связанных коммитов в графе стало 3.
Теперь мы хотим создать новую ветку dev на основе самого первого коммита в ветке master. Сначала переместим указатель на текущую ветку HEAD на первый коммит в ветке master. Для этого нам понадобится команда git checkout, с помощью которой можно переключиться на нужную ветку по её имени или на нужный коммит по его хэшу:
~/repo$ git checkout 902fffb0f20c66f37366681722465e4e4edd7e2c
HEAD is now at 902fffb Initial commit
~/repo$ git log --graph --name-status --pretty=oneline --all
* d2062c36a8bcf56edc46a6bc69b254b371c40b22 (master) Add features
| M app.py
| M compute.c
| D README.md
* fa6960d552a199adea9151189d267f62e69d96cc Accelerate computations
| A compute.c
| M README.md
* 902fffb0f20c66f37366681722465e4e4edd7e2c (HEAD) Initial commit
A app.py
A README.md
Обратите внимание, при пересоздании репозитория хэши коммитов будут отличаться. Команда git log теперь используется с дополнительной опцией --all, позволяющей включить в вывод в консоль все ветки в репозитории.
Как видно из графа коммитов, указатель HEAD переместился на первый коммит в ветке master. Создадим новую ветку dev на основе этого коммита, и добавим в ветку dev новый коммит:
~/repo$ git checkout -b dev
Switched to a new branch 'dev'
~/repo$ echo "Sample app with tests" > README.md
~/repo$ echo "def test(): assert True" > tests.py
~/repo$ git add .
~/repo$ git diff --cached --stat
README.md | 2 +-
tests.py | 1 +
2 files changed, 2 insertions(+), 1 deletion(-)
~/repo$ git commit -m "Add unit tests"
[dev 4c19b34] Add unit tests
2 files changed, 2 insertions(+), 1 deletion(-)
create mode 100644 tests.py
~/repo$ git log --graph --name-status --pretty=oneline --all
* 4c19b344abd9dede5a028bb29357e98d49943622 (HEAD -> dev) Add unit tests
| M README.md
| A tests.py
| * d2062c36a8bcf56edc46a6bc69b254b371c40b22 (master) Add features
| | M app.py
| | M compute.c
| | D README.md
| * fa6960d552a199adea9151189d267f62e69d96cc Accelerate computations
|/
| A compute.c
| M README.md
* 902fffb0f20c66f37366681722465e4e4edd7e2c Initial commit
A app.py
A README.md
В графе коммитов теперь видны 2 ветки и 4 коммита.
Выполним слияние ветки master без последнего коммита с веткой dev. Для этого воспользуемся командой git merge, указав в качестве аргумента хэш коммита, слияние с которым хотим выполнить:
~/repo$ git merge fa6960d552a199adea9151189d267f62e69d96cc
Auto-merging README.md
CONFLICT (content): Merge conflict in README.md
Automatic merge failed; fix conflicts and then commit the result.
~/repo$ cat README.md
<<<<<<< HEAD
Sample app with tests
=======
Sample app with C code
>>>>>>> fa6960d552a199adea9151189d267f62e69d96cc
В процессе слияния веток возникли конфликты, которые git предлагает исправить вручную.
При командной разработке программного обеспечения нередко возникают конфликты слияния. Их наличие связано с тем, что работа над одним и тем же файлом с исходным кодом может вестись одновременно и независимо в разных ветках git-репозитория. Рано или поздно изменения из разных веток придётся объединять – принимать решение, какие фрагменты кода оставить в новой версии файла после слияния, а какие – удалить или заменить новыми. В случае, если git не может разрешить конфликты автоматически, разные версии изменившегося фрагмента файла помещаются в его новую версию с разделителями из символов <, = и >.
Разрешим конфликты вручную, сохранив в новой версии файла README.md его содержимое как из текущей ветки HEAD, так и из ветки master, с коммитом fa6960d552a199adea9151189d267f62e69d96cc из которой сейчас производится слияние. Для этого обновим содержимое файла README.md, добавим файл в область индексирования и сделаем новый коммит:
~/repo$ echo "Sample app with tests and C code" > README.md
~/repo$ git add .
~/repo$ git commit -m "Merge branch 'master' into dev"
[dev 0c8489d] Merge branch 'master' into dev
Переключим указатель HEAD на ветку master и визуализируем граф коммитов:
~/repo$ git checkout master
Switched to branch 'master'
~/repo$ git log --graph --name-status --pretty=oneline --all
* 0c8489d26761a0ed6968ebc9e453749264e278ad (dev) Merge branch 'master' into dev
|\
* | 4c19b344abd9dede5a028bb29357e98d49943622 Add unit tests
| | M readme.md
| | A tests.py
| | * d2062c36a8bcf56edc46a6bc69b254b371c40b22 (HEAD -> master) Add features
| |/
| | M app.py
| | M compute.c
| | D readme.md
| * fa6960d552a199adea9151189d267f62e69d96cc Accelerate computations
|/
| A compute.c
| M readme.md
* 902fffb0f20c66f37366681722465e4e4edd7e2c Initial commit
A app.py
A readme.md
8.1.2. Упражнения
В приведённых задачах необходимо создать в командной строке git-репозиторий, соответствующий указанному логу. Для проверки используйте команду: git log --graph --name-status --pretty=oneline --all --decorate
Задача 1.
* (HEAD -> master) Rundown deface deodorize?
| R100 linoleum.py spider.c
* Merge branch 'carnation'
|\
| * (carnation) fiftieth anatomist country
| | M landlord.txt
| * Dating dangle liability.
| | A drench
| | A spirited.h
| * (spearman) Jailbreak humility unworthy!
| | M handiwork.ini
| | M landlord.txt
* | Deception boundless!
|/
| M handiwork.ini
| A linoleum.py
* Lecturer entering?
A handiwork.ini
A landlord.txt
Задача 2.
* (HEAD -> overpay) tiny decimeter
| M doormat.py
* (master) Merge branch 'booth'
|\
| * (booth) Chatroom radiation unrobed?
| | A feminize.yaml
| * animosity
| | R100 doormat.py stress.h
* | trout
|/
| M doormat.py
| M revolt.ini
* Kooky unhook?
| A doormat.py
| A revolt.ini
| D wound.c
* Chip projector?
A wound.c
Задача 3.
* (HEAD -> master) Merge branch 'mumble'
|\
| * (mumble) Anyhow anemic?
| | R100 expedited.c coconut.c
* | Splotchy!
|/
| A confused.h
* coveting skinhead
| M crook.yaml
| M expedited.c
* tutu
| M crook.yaml
| A expedited.c
* Sullen jury.
A crook.yaml
Задача 4.
* (HEAD -> master) Merge branch 'dusk'
|\
| * (dusk) Traverse?
| | R100 operator.ini compactor.h
| | R100 stargazer.yaml reshape.h
* | Stained send curfew?
| | M chariot.c
| | M expire
* | Grandkid favorably octagon.
|/
| R100 afflicted.c expire
* parchment
| A afflicted.c
* Covenant agency convene.
A chariot.c
A operator.ini
A stargazer.yaml
Задача 5.
* (HEAD -> backtrack) Magnetic hatbox baguette.
| M unrigged.json
* Whacky craftily.
| A strive.c
* unlocked bush
| A neatness.ini
| M unrigged.json
* (superior) Merge branch 'master' into superior
|\
| * (master) devious recent bust
| | A neatness.ini
* | Subsonic sweep!
| | D strive.c
* | Class negligent zipfile?
|/
| M unrigged.json
* twelve trinity halt
A strive.c
A unrigged.json
8.2. Разрешение зависимостей пакета
8.2. Разрешение зависимостей пакета
8.2.1. Разбор задачи
Рассмотрим задачу разрешения зависимостей пакета, граф зависимостей которого показан на рис. 44:

Зависимости разрешаются для пакета app, необходимо найти минимальное по числу пакетов решение.
В приведённом графе стрелки, соединяющие пакеты, обозначают факт наличия зависимости одного пакета от другого пакета. Например, из графа зависимостей следует, что для корректной работы пакета app версии 1.0.0 необходимо установить пакет react версии 3.1.0.
В том случае, если пакет заданной версии соединён несколькими стрелками с несколькими версиями другого пакета, то это значит, что тот пакет, из которого исходят стрелки, совместим с несколькими версиями другого пакета. Так, например, в приведённом выше графе зависимостей пакет app совместим с любой из версий пакета monaco-editor – как с monaco-editor 2.3.0, так и с monaco-editor 2.2.0. Поскольку речь идёт о минимальном по числу пакетов решении, необходимо выбрать одну из версий пакета monaco-editor, проверив транзитивные зависимости пакета app на наличие конфликтов версий.
При выборе пакета monaco-editor версии 2.3.0 возникает конфликт: monaco-editor одновременно требует установки пакета lodash 2.6.0 и пакета @replit/codemirror-css-color-picker 3.3.0, при этом пакет @replit/codemirror-css-color-picker 3.3.0 совместим только с lodash 2.5.0. Значит, разрешить зависимости для monaco-editor 2.3.0 не получится.
Аналогичным образом проверив другие подграфы легко найти решение, минимальное по числу пакетов:
- Установить
app1.0.0. - Установить
monaco-editor2.2.0. - Установить
@replit/codemirror-css-color-picker3.4.0. - Установить
react3.1.0. - Не устанавливать
lodash.
Выделим на графе зависимостей рис. 44 выбранные версии пакетов символом «✓», а символом «✕» – один из конфликтов версий. Результат показан на рис. 45:

Рассматриваемый граф зависимостей также может быть представлен в виде булевой формулы.
Введём следующие обозначения:
- Пакет
appобозначим как \(a\). - Пакет
monaco-editor– как \(m\). - Пакет
@replit/codemirror-css-color-picker– как \(c\). - Пакет
lodash– как \(l\). - Пакет
react– как \(r\).
Версию пакета будем указывать справа от его имени. Тогда формула с логическими переменными для графа, показанного на рис. 44, будет иметь вид:
| $$ \begin{align} ( a_{1.0.0} \implies m_{2.3.0} \lor m_{2.2.0} ) \land ( a_{1.0.0} \implies r_{3.1.0} ) \land ( m_{2.3.0} \implies c_{3.3.0} ) \land \\ ( m_{2.3.0} \implies l_{2.6.0} ) \land ( m_{2.2.0} \implies c_{3.5.0} \lor c_{3.4.0} ) \land ( c_{3.5.0} \implies l_{2.6.0} ) \land \\ ( c_{3.5.0} \implies r_{3.2.0} ) \land ( c_{3.4.0} \implies r_{3.1.0} ) \land ( c_{3.3.0} \implies l_{2.5.0} ) \land \\ ( c_{3.3.0} \implies r_{3.2.0} ) \land a_{1.0.0}. \end{align} $$ | (5) |
Легко убедиться, что при выбранных вручную версиях пакетов \(a_{1.0.0}\), \(m_{2.2.0}\), \(c_{3.4.0}\) и \(r_{3.1.0}\) формула выполняется, при этом найденное решение является минимальным по числу пакетов. На практике задачи выполнимости булевых формул, таких как формула (5), решаются при помощи SAT-решателей.
8.2.2. Упражнения
В приведенных задачах необходимо правильно выбрать версии пакетов, чтобы обеспечивалось минимальное по числу пакетов решение.
Задача 1. Решите задачу разрешения зависимостей для пакета xcite:

Задача 2. Решите задачу разрешения зависимостей для пакета ruby.erubis:

Задача 3. Решите задачу разрешения зависимостей для пакета libcgicc.dev:

Задача 4. Решите задачу разрешения зависимостей для пакета Sysvinit:

Задача 5. Решите задачу разрешения зависимостей для пакета scim-unikey:

Список литературы
1. The Missing Semester of Your CS Education [Онлайн]. — URL: https://missing.csail.mit.edu/ .
2. Irving D., Hertweck K., Johnston L., Ostblom J., Wickham C., Wilson G. Research software engineering with python: Building software that makes research possible . — Chapman ; Hall/CRC, 2021.
3. Робачевский Л. М., Немнюгин С. Л., Стесик О. Л. Операционная система UNIX. — 2-е изд., перераб. и доп. — СПб.: БХВ-Петербург, 2010. — С. 635.
4. Ramey C. The Bourne-Again SHell // The Architecture of Open Source Applications. — 2011.
5. ShellCheck – shell script analysis tool [Онлайн]. — URL: https://www.shellcheck.net/ .
6. regex101: build, test, and debug regex [Онлайн]. — URL: https://regex101.com/ .
7. Janssens J. Data Science at the Command Line . — O’Reilly Media, Inc., 2021.
8. Советов П. Н. Конфигурационное управление: Учебное пособие. — М.: МИРЭА – Российский технологический университет, 2021.
9. Elm Syntax. Operators [Онлайн]. — URL: https://elm-lang.org/docs/syntax#operators .
10. F# Language Reference: Symbol and Operator Reference [Онлайн]. — URL: https://learn.microsoft.com/en-us/dotnet/fsharp/language-reference/symbol-and-operator-reference/#function-symbols-and-operators .
11. TC39. ES Pipe Operator [Онлайн]. — 2021. — URL: https://tc39.es/proposal-pipeline-operator/ .
12. Советов П. Н. Программирование на языке Питон: Учебное пособие. — М.: МИРЭА – Российский технологический университет, 2021.
13. PEP 255 – Simple Generators [Онлайн]. — URL: https://peps.python.org/pep-0255/ .
14. Graphviz. Open source graph visualization software [Онлайн]. — 2025. — URL: https://graphviz.org/ .
15. Введение в JSON [Онлайн]. — URL: https://www.json.org/json-ru.html .
16. Pretty-print tabular data in Python, a library and a command-line utility [Онлайн]. — URL: https://github.com/astanin/python-tabulate .
17. Command-line JSON processor [Онлайн]. — URL: https://jqlang.github.io/jq/ .
18. A suite of utilities for converting to and working with CSV, the king of tabular file formats. [Онлайн]. — URL: https://csvkit.readthedocs.io/en/latest/ .
19. Aho A. V., Kernighan B. W., Weinberger P. J. The AWK programming language. — Addison-Wesley Professional, 2023.
20. Портал открытых данных Правительства Москвы: Бассейны плавательные крытые [Онлайн]. — URL: https://data.mos.ru/opendata/890 .
21. Хопкрофт Д. Э., Мотвани Р., Ульман Д. Введение в теорию автоматов, языков и вычислений. — Вильямс, 2008.
22. Hirsch J. E. An index to quantify an individual’s scientific research output / Proceedings of the National Academy of Sciences. — 2005. — Т. 102. — С. 16569–16572.
23. Онлайн-руководство по наукометрии [Онлайн]. — URL: https://sciguide.hse.ru/ .
24. Elibrary — Список публикаций автора [Онлайн]. — URL: https://elibrary.ru/author_items.asp?authorid=260020 .
25. Beautiful Soup Documentation [Онлайн]. — URL: https://www.crummy.com/software/BeautifulSoup/bs4/doc/ .
26. PEP 634 – Structural Pattern Matching: Specification [Онлайн]. — URL: https://peps.python.org/pep-0634/ .
27. Tucker C., Shuffelton D., Jhala R., Lerner S. Opium: Optimal package install/uninstall manager / 29th International Conference on Software Engineering (ICSE’07). — IEEE, 2007. — С. 178–188.
28. The package manager for Dart [Онлайн]. — URL: https://github.com/dart-lang/pub .
29. Abate P., Di Cosmo R., Gousios G., Zacchiroli S. Dependency solving is still hard, but we are getting better at it / 2020 IEEE 27th International Conference on Software Analysis, Evolution and Reengineering (SANER). — IEEE, 2020. — С. 547–551.
30. Debian Package Management [Онлайн]. — URL: https://wiki.debian.org/PackageManagement .
31. Tiny Python Library for Graph Drawing in yEd [Онлайн]. — URL: https://github.com/true-grue/yed_py .
32. yEd — graph editor. High-quality diagrams made easy [Онлайн]. — URL: https://www.yworks.com/products/yed .
33. Di Cosmo R., Durak B., Leroy X., Mancinelli F., Vouillon J. Maintaining large software distributions: new challenges from the FOSS era / Proceedings of the FRCSS 2006 workshop. — EASST, 2006. — С. 7–20.
34. The Z3 Theorem Prover [Онлайн]. — URL: https://github.com/Z3Prover/z3 .
35. A MiniZinc Tutorial [Онлайн]. — URL: https://docs.minizinc.dev/en/2.5.5/part_2_tutorial.html .
36. Chacon S., Straub B. Pro Git, 2nd ed. — Apress, 2014. — С. 456.
37. Левенштейн В. И. Двоичные коды с исправлением выпадений, вставок и замещений символов / Доклады Академии наук. — Российская академия наук, 1965. — Т. 163. — С. 845–848.
38. Jsonnet. A configuration language for app and tool developers [Онлайн]. — URL: https://jsonnet.org/ .
39. The Dhall configuration language [Онлайн]. — URL: https://dhall-lang.org/ .
40. The Configuration Complexity Clock [Онлайн]. — URL: https://mikehadlow.blogspot.com/2012/05/configuration-complexity-clock.html?m=1 .
41. Wlaschin S. Domain Modeling Made Functional: Tackle Software Complexity with Domain-Driven Design and F. — The Pragmatic Bookshelf, 2018.
42. ANTLR [Онлайн]. — URL: https://www.antlr.org/ .
43. Sly Lex Yacc [Онлайн]. — URL: https://github.com/dabeaz/sly .
44. Mokhov A., Mitchell N., Jones S. P. Build systems à la carte: Theory and practice // Journal of Functional Programming. — Cambridge University Press, 2020. — Т. 30.
45. Речистов Г. С., Елюгин Е. А., Иванов А. А. Программное моделирование вычислительных систем . — 2016.
46. Pandoc User’s Guide [Онлайн]. — URL: https://pandoc.org/MANUAL.html .